[Hadoop] Hdfs Data Integrity with Checksum
使用 Spark/Hadoop 生態系這麼久之後,最近才開始來研究 Hadoop 的 checksum 機制是怎麼運作的?
詳細內容想方涉法, France, Taiwan, Health, Information Technology

使用 Spark/Hadoop 生態系這麼久之後,最近才開始來研究 Hadoop 的 checksum 機制是怎麼運作的?
詳細內容
最近在研究如何在 K8S 上面跑一個 On-Demand 的 Spark Cluster 服務,基本上有兩條路可以走,一條是利用 k8s 的 Deployment 來自建 Spark Cluster,另外一條路則是利用 Kubernetes 既有與 Spark 對接的介面 (這邊是利用 spark-submit) 來實作,概念上就是直接執行一個類似下方的指令,所以想要擁有一個 On-Demand Spark Cluster on AKS 這兩種方法個有什麼優劣?
詳細內容K8S 服務在業界已經是很常用的一個叢集管理技術了,在這邊記錄一些 K8S 的常用指令與利用 Azure Kubernetes 服務實作的一些輸出,關於 Kubernetes 的介紹可以參考以下的 Youtube 影片,讀文件很累的時候可以聽聽 IBM 的工程師是怎麼介紹 K8S。
詳細內容
在前一篇筆者介紹有關法國預售屋的購買時程,有提到交屋前六至九個月的 Visite Cloison,Visite Cloison 筆者嘗試翻譯成探訪分區監工,雖然 Cloison 有隔間的意思在裡面,但是法文解釋的 Visite Cloison 為 Une Visite de Chantier qui vous permit de vérifier la conformité de travaux,所以其本質就是讓你到工地裡去監工,本篇參考 SeLoger Neuf 的網站關於 Visite Cloison 工地監工的介紹來講解一下買房時 Visite Cloison 探訪分區監工的一些注意事項。
詳細內容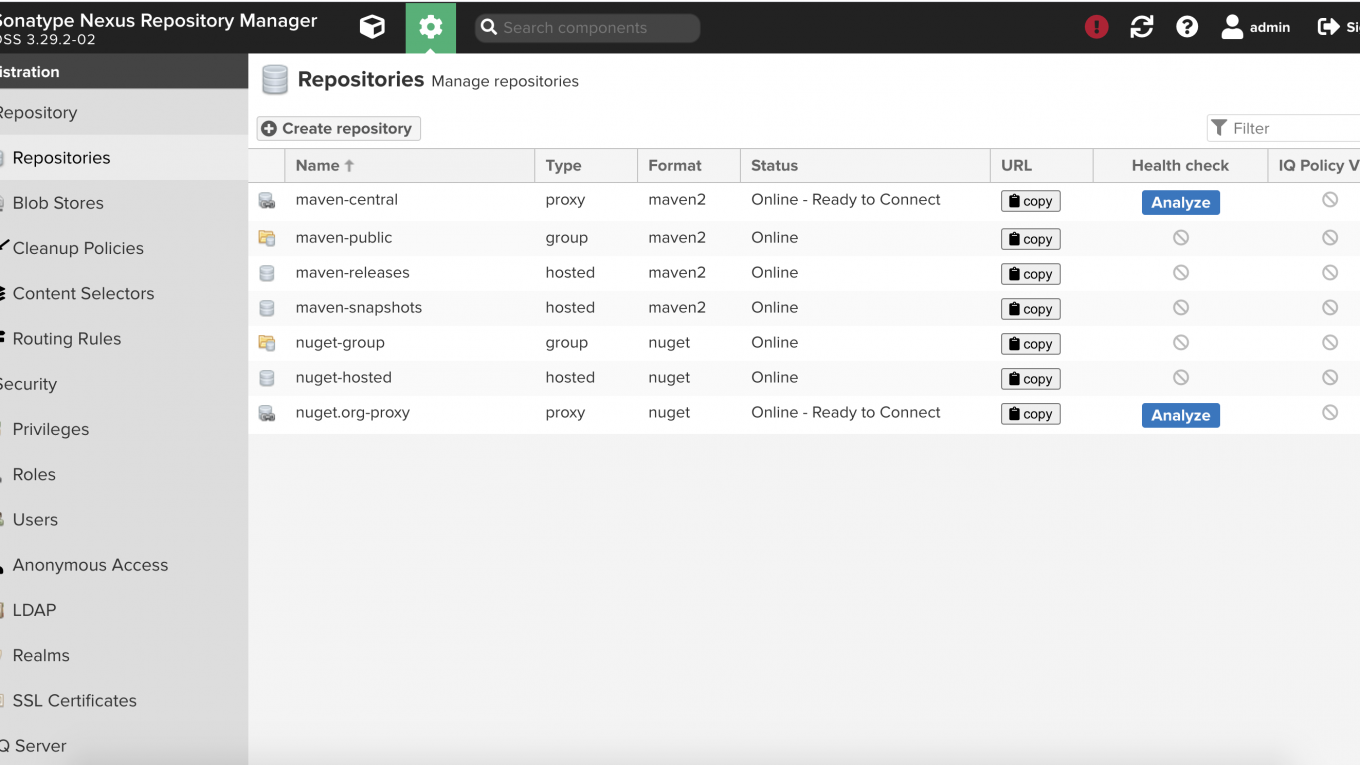
🍋 爸在法國擔任資料工程師的時候,頻繁地使用過 Nexus 這個資源庫倉儲系統,那時候使用 Nexus 主要的原因是因為在一間大公司裡面,常常各個部門之間的專案是互相依賴的,此時為了建置 CICD 的管理機制,他們會導入 Nexus 這樣的系統來分享自己編譯好的 Jar 檔(如果是 Java, Scala 的開發環境),所有使用過 Maven 編譯的開發者應該會 nexus 也不陌生,很多著名的專案都是利用 Nexus 這樣的系統在分享他們的開源程式,例如 Apache Spark 等等,那時候🍋 爸主要是使用為主,本篇要介紹如何部署屬於自己的 Nexus Repository ?
詳細內容
這是一本讓人一打開就想要一直看下去的書。檸檬媽在 Hyread 隨身圖書館上搜尋下ㄧ本要看的書時,看到這本「爸爸的蝴蝶結」,書名不太吸引人,但沒想到光在試閱內容時就停不下來,馬上借閱來看,在看的過程中也數度流下眼淚(真的不誇張!雖然檸檬媽也是個愛哭鬼啦~)
詳細內容
疫情下的新服務,法國郵局的服務涵蓋列印資料並寄出呢!檸檬媽試了幾次,覺得超級方便的,不但不用自己信資料,還不用出門,馬上變成寄信愛好者(哈~太誇張了!)。
詳細內容
在國外住過的大家,想必都會遇到當地人詢問「臺灣在哪裡?」、「臺灣的特色是什麼?」、「臺灣的歷史是什麼呢?」,像檸檬媽就常常被問這方面的問題。當你粗略地瞭解臺灣歷史後,就可以在出國或國外生活時,和遇到的人暢所欲言,好好的介紹臺灣呢(不用怕沒話題XD)!這也是檸檬媽興起要寫介紹臺灣歷史心得文的緣由。
詳細內容
提出選擇/意見(Proposer)的用法非常實用,邀約朋友時常會使用到。提出選擇的 7 種表達方式:1. 我建議… Je propose que… 2. 我建議… Je propose de… 3. 您覺得…如何? Qu’est-ce que vous diriez de…?4. 你覺得…如何 Qu’est-ce que tu dirais de…?5. 我們可以… Nous pourrions… 6. 我們可以… On pourrait… 7. 那麼我們…好嗎 (Et) si… ?
詳細內容
讀完第一本「說給兒童的臺灣歷史」,是不是很期待接下來的故事呢?在第二本書中,介紹「鄭成功」和其子「鄭經」對臺灣的供獻,以及後來「施琅」提出的「渡海禁令」,導致臺灣安寧社會的破壞。歷史的事件不全然都是美好的,但就是這些點點滴滴造就了現在的臺灣,讓我們來細細品味其中的滋味吧!
詳細內容