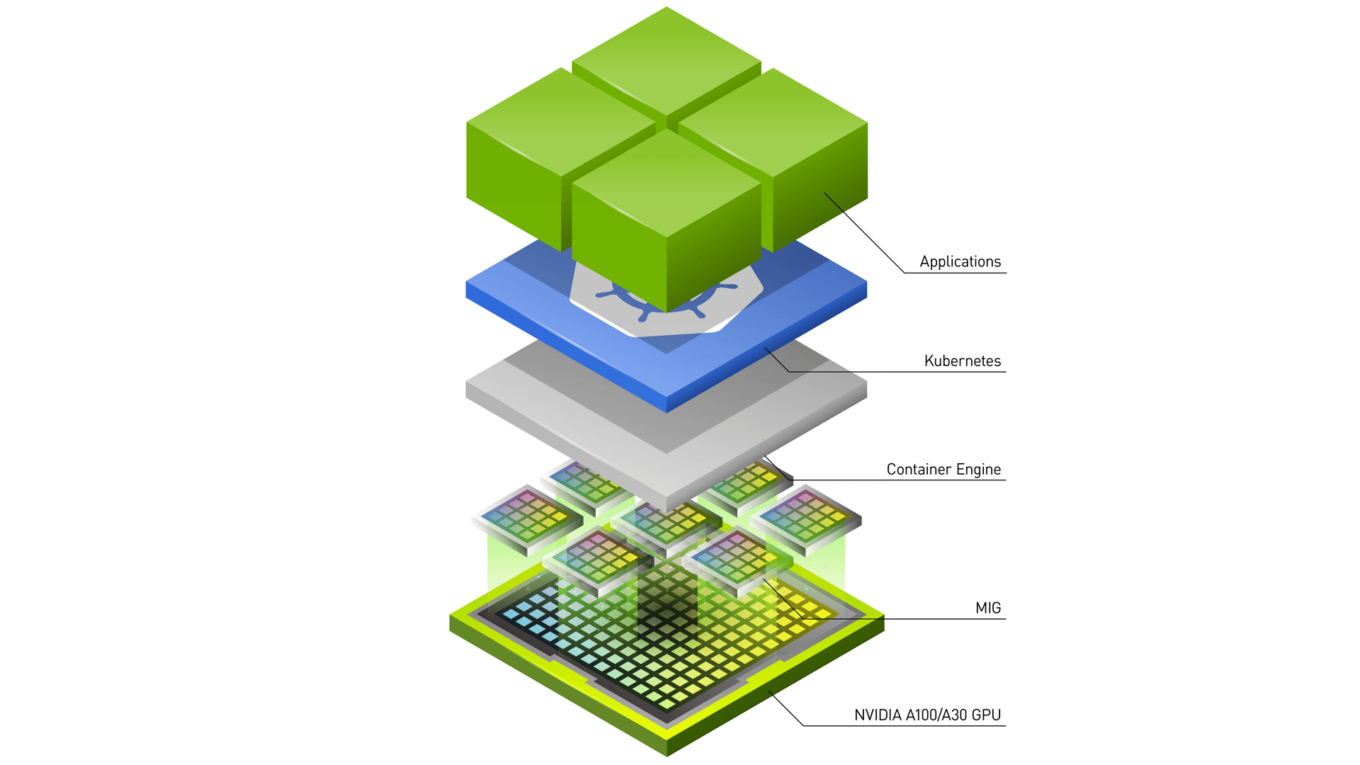
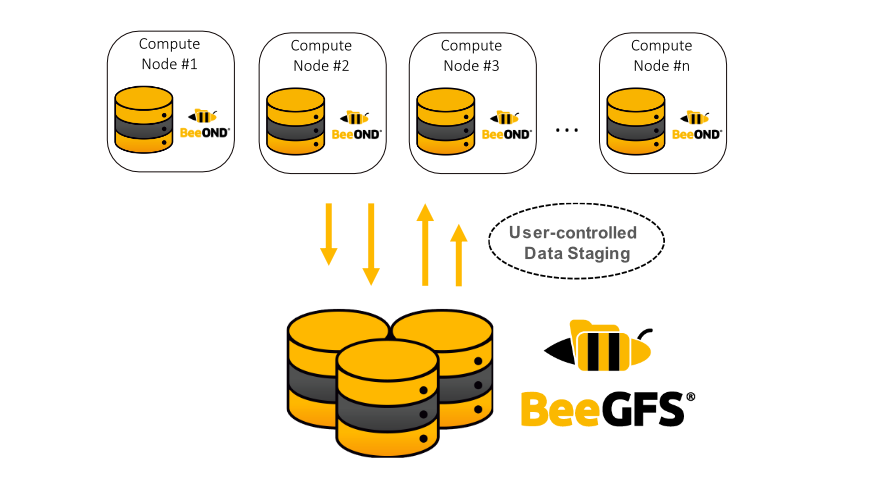
[GCP] Spark Hadoop Access with Requester Pays
在生醫領域有很多開放資料都是存在 Google Cloud Platform (GCP),有時候要避免大量複製檔案,我們會想要直接使用 gs:// 開頭的開放資料當作 Spark Table 的後端路徑,與 AWS 與 Azure 不同的是 GCP Dataproc 提供了一個使用者付費的方式,顧名思義就是資料的傳輸費用是由使用者去支付的,本篇紀錄如何設定 Spark Cluster 的設定檔透過 Spark SQL 的方式直接使用公開的資料,減少複製檔案與儲存帶來的成本。
詳細內容