[Hive] Hive Server with Spark Standalone
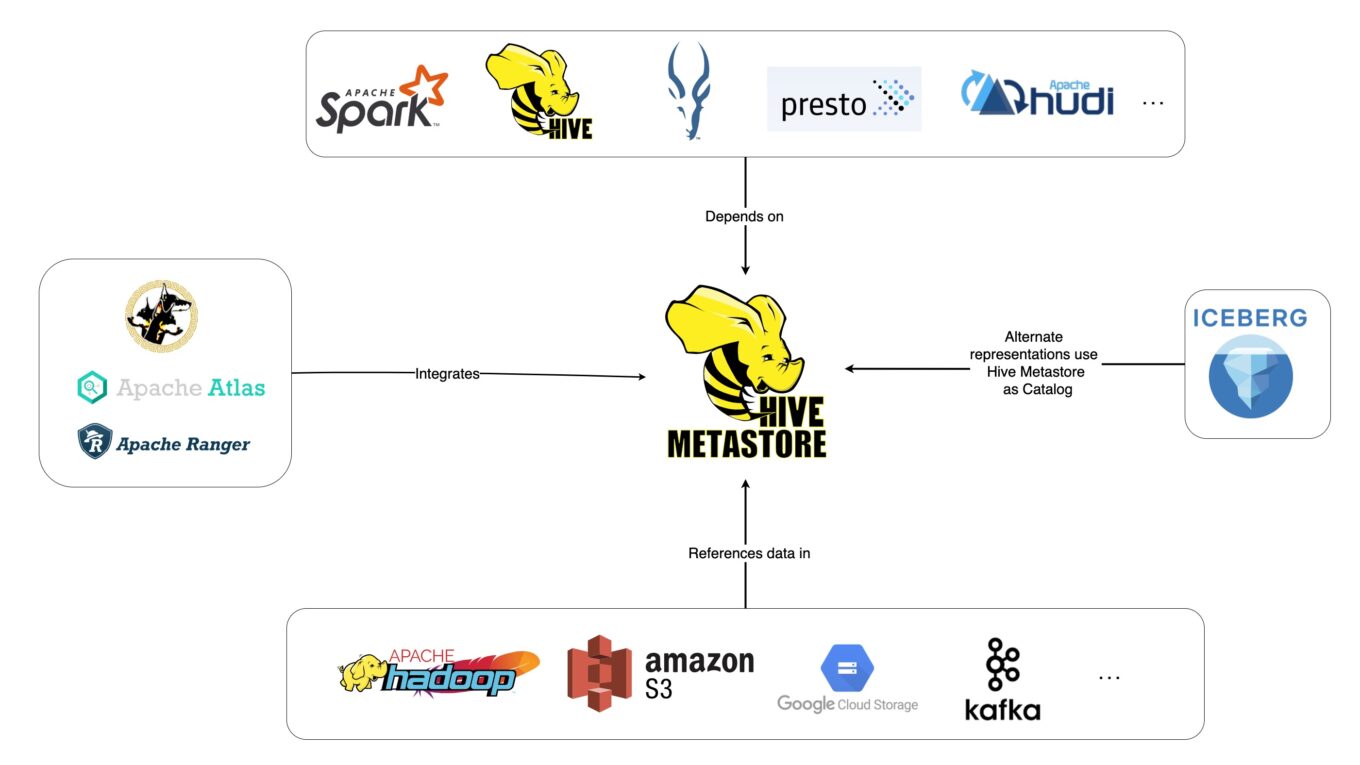
在上一篇我們介紹了如何利用 MySQL 服務建立屬於自己的 Hive Metastore 資料庫,並且利用 Spark SQL 的方式對 Metastore 裡面的資料做存取,根據上方圖示,我們可以理解除了 Spark 可以對 Hive Metastore 做存儲之外,我們也可以利用 Hive, Impala, Presto, Apache Hudi 甚至是最近出來的 Apache Superset 來做資料串接,本篇想要紀錄並且比較這幾種技術的優缺點是什麼?
Hive Server
第一種方式取得 Hive Metastore 資料的方式是透過 Hive Server,參考實作方式網站1,網站2。
啟動 Metastore Server 指令,如果想要進一步取得一些系統資訊,可以加上 –hiveconf 參數
cd /opt/hive/bin
./hive --service metastore &
./hive --service metastore --hiveconf hive.root.logger=INFO,console &啟動 Hive Server 2 指令:
cd /opt/hive/bin
./hive --service hiveserver2 &在開啟 Metastore Server 與 Hive Server2 之後L我們嘗試利用 Beeline 去連接,得到以下的錯誤訊息,訊息顯示 /tmp/hive/java 資料夾沒有寫入的權限:
root@22c98e215f2d:/opt/hive/bin$ ./beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/apache-hive-3.1.3-bin/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html$multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.3 by Apache Hive
beeline> !connect jdbc:hive2://
Connecting to jdbc:hive2://
Enter username for jdbc:hive2://: root
Enter password for jdbc:hive2://: ****
Hive Session ID = d8236e49-49be-4b98-b4fa-ee8110c3cf2c
Error applying authorization policy on hive configuration: The dir: /tmp/hive on HDFS should be writable. Current permissions are: rwxr-xr-x
0: jdbc:hive2:// (closed)> Connection is already closed.在給予寫入權限之後成功透過 Beeline 連線至 HiveServer2 如下顯示,只不過所有儲存在 Hive Metastore 上面的 Azure Gen2 路徑在讀取的時候會發生錯誤:
root@22c98e215f2d:/opt/hive/bin$ ./beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/apache-hive-3.1.3-bin/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html$multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.3 by Apache Hive
beeline> !connect jdbc:hive2://
Connecting to jdbc:hive2://
Enter username for jdbc:hive2://: root
Enter password for jdbc:hive2://: ****
Hive Session ID = 5c324202-a99b-453d-b93f-3c256b9754c9
23/04/09 09:29:42 [main]: WARN session.SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory.
23/04/09 09:29:42 [main]: WARN metastore.ObjectStore: datanucleus.autoStartMechanismMode is set to unsupported value null . Setting it to value: ignored
23/04/09 09:29:44 [main]: WARN DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
23/04/09 09:29:44 [main]: WARN DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
23/04/09 09:29:44 [main]: WARN DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
23/04/09 09:29:44 [main]: WARN DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
23/04/09 09:29:44 [main]: WARN DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
23/04/09 09:29:44 [main]: WARN DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
23/04/09 09:29:45 [main]: WARN DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
23/04/09 09:29:45 [main]: WARN DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
23/04/09 09:29:45 [main]: WARN DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
23/04/09 09:29:45 [main]: WARN DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
23/04/09 09:29:45 [main]: WARN DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
23/04/09 09:29:45 [main]: WARN DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://>
0: jdbc:hive2://> SHOW TABLES;
OK
+-----------+
| tab_name |
+-----------+
| employee |
+-----------+
2 rows selected (0.13 seconds)
0: jdbc:hive2://> SELECT * FROM employee;
OK
23/04/09 09:35:00 [232657a1-cf1d-41cc-a51d-f01da87cf43c main]: WARN fs.FileSystem: Failed to initialize fileystem abfss://xxxx@storage.dfs.core.windows.net/user/hive/warehouse/employee: Configuration property storage.dfs.core.windows.net not found.
23/04/09 09:35:00 [main]: WARN thrift.ThriftCLIService: Error fetching results:
org.apache.hive.service.cli.HiveSQLException: java.io.IOException: Configuration property sponsorwus2f40castorage.dfs.core.windows.net not found.
at org.apache.hive.service.cli.operation.SQLOperation.getNextRowSet(SQLOperation.java:465) ~[hive-service-3.1.3.jar:3.1.3]
at org.apache.hive.service.cli.operation.OperationManager.getOperationNextRowSet(OperationManager.java:309) ~[hive-service-3.1.3.jar:3.1.3]
at org.apache.hive.service.cli.session.HiveSessionImpl.fetchResults(HiveSessionImpl.java:905) ~[hive-service-3.1.3.jar:3.1.3]
at org.apache.hive.service.cli.CLIService.fetchResults(CLIService.java:561) ~[hive-service-3.1.3.jar:3.1.3]
at org.apache.hive.service.cli.thrift.ThriftCLIService.FetchResults(ThriftCLIService.java:786) [hive-service-3.1.3.jar:3.1.3]
at sun.reflect.GeneratedMethodAccessor3.invoke(Unknown Source) ~[?:?]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_362]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_362]
at org.apache.hive.jdbc.HiveConnection$SynchronizedHandler.invoke(HiveConnection.java:1585) [hive-jdbc-3.1.3.jar:3.1.3]
at com.sun.proxy.$Proxy33.FetchResults(Unknown Source) [?:?]
at org.apache.hive.jdbc.HiveQueryResultSet.next(HiveQueryResultSet.java:373) [hive-jdbc-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.BufferedRows.<init>(BufferedRows.java:56) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.IncrementalRowsWithNormalization.<init>(IncrementalRowsWithNormalization.java:50) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.BeeLine.print(BeeLine.java:2250) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.Commands.executeInternal(Commands.java:1026) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.Commands.execute(Commands.java:1201) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.Commands.sql(Commands.java:1130) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.BeeLine.dispatch(BeeLine.java:1425) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.BeeLine.execute(BeeLine.java:1287) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.BeeLine.begin(BeeLine.java:1071) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.BeeLine.mainWithInputRedirection(BeeLine.java:538) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.BeeLine.main(BeeLine.java:520) [hive-beeline-3.1.3.jar:3.1.3]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_362]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_362]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_362]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_362]
at org.apache.hadoop.util.RunJar.run(RunJar.java:323) [hadoop-common-3.3.0.jar:?]
at org.apache.hadoop.util.RunJar.main(RunJar.java:236) [hadoop-common-3.3.0.jar:?]
Caused by: java.io.IOException: Configuration property sponsorwus2f40castorage.dfs.core.windows.net not found.
at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextRow(FetchOperator.java:602) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.exec.FetchOperator.pushRow(FetchOperator.java:509) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.exec.FetchTask.fetch(FetchTask.java:146) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.Driver.getResults(Driver.java:2691) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.getResults(ReExecDriver.java:229) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hive.service.cli.operation.SQLOperation.getNextRowSet(SQLOperation.java:460) ~[hive-service-3.1.3.jar:3.1.3]
... 27 more
Caused by: org.apache.hadoop.fs.azurebfs.contracts.exceptions.ConfigurationPropertyNotFoundException: Configuration property sponsorwus2f40castorage.dfs.core.windows.net not found.
at org.apache.hadoop.fs.azurebfs.AbfsConfiguration.getStorageAccountKey(AbfsConfiguration.java:399) ~[hadoop-azure-3.3.0.jar:?]
at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystemStore.initializeClient(AzureBlobFileSystemStore.java:1164) ~[hadoop-azure-3.3.0.jar:?]
at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystemStore.<init>(AzureBlobFileSystemStore.java:180) ~[hadoop-azure-3.3.0.jar:?]
at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem.initialize(AzureBlobFileSystem.java:108) ~[hadoop-azure-3.3.0.jar:?]
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:3414) ~[hadoop-common-3.3.0.jar:?]
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:158) ~[hadoop-common-3.3.0.jar:?]
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:3474) ~[hadoop-common-3.3.0.jar:?]
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:3442) ~[hadoop-common-3.3.0.jar:?]
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:524) ~[hadoop-common-3.3.0.jar:?]
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:365) ~[hadoop-common-3.3.0.jar:?]
at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextPath(FetchOperator.java:276) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextSplits(FetchOperator.java:370) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.exec.FetchOperator.getRecordReader(FetchOperator.java:314) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextRow(FetchOperator.java:540) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.exec.FetchOperator.pushRow(FetchOperator.java:509) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.exec.FetchTask.fetch(FetchTask.java:146) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.Driver.getResults(Driver.java:2691) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.getResults(ReExecDriver.java:229) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hive.service.cli.operation.SQLOperation.getNextRowSet(SQLOperation.java:460) ~[hive-service-3.1.3.jar:3.1.3]
... 27 more
Error: java.io.IOException: Configuration property sponsorwus2f40castorage.dfs.core.windows.net not found. (state=,code=0)
0: jdbc:hive2://>可能的解決方法是透過 Hive Connection with Azure Blob Storage,參考網站,再填入了 abfss 相關的環境參數到 hadoop core-site.xml 之後,執行 SQL Query 的指令變成了以下:
0: jdbc:hive2://> SELECT * FROM table LIMIT 10;
OK
23/04/10 01:01:29 [main]: WARN thrift.ThriftCLIService: Error fetching results:
org.apache.hive.service.cli.HiveSQLException: java.io.IOException: java.io.IOException: abfss://xxxxxx@storage.dfs.core.windows.net/user/hive/warehouse/table/part-00000-997a0587-3935-4e06-bca0-632dee826842-c000.snappy.parquet not a SequenceFile
at org.apache.hive.service.cli.operation.SQLOperation.getNextRowSet(SQLOperation.java:465) ~[hive-service-3.1.3.jar:3.1.3]
at org.apache.hive.service.cli.operation.OperationManager.getOperationNextRowSet(OperationManager.java:309) ~[hive-service-3.1.3.jar:3.1.3]
at org.apache.hive.service.cli.session.HiveSessionImpl.fetchResults(HiveSessionImpl.java:905) ~[hive-service-3.1.3.jar:3.1.3]
at org.apache.hive.service.cli.CLIService.fetchResults(CLIService.java:561) ~[hive-service-3.1.3.jar:3.1.3]
at org.apache.hive.service.cli.thrift.ThriftCLIService.FetchResults(ThriftCLIService.java:786) [hive-service-3.1.3.jar:3.1.3]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_362]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_362]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_362]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_362]
at org.apache.hive.jdbc.HiveConnection$SynchronizedHandler.invoke(HiveConnection.java:1585) [hive-jdbc-3.1.3.jar:3.1.3]
at com.sun.proxy.$Proxy37.FetchResults(Unknown Source) [?:?]
at org.apache.hive.jdbc.HiveQueryResultSet.next(HiveQueryResultSet.java:373) [hive-jdbc-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.BufferedRows.<init>(BufferedRows.java:56) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.IncrementalRowsWithNormalization.<init>(IncrementalRowsWithNormalization.java:50) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.BeeLine.print(BeeLine.java:2250) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.Commands.executeInternal(Commands.java:1026) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.Commands.execute(Commands.java:1201) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.Commands.sql(Commands.java:1130) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.BeeLine.dispatch(BeeLine.java:1425) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.BeeLine.execute(BeeLine.java:1287) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.BeeLine.begin(BeeLine.java:1071) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.BeeLine.mainWithInputRedirection(BeeLine.java:538) [hive-beeline-3.1.3.jar:3.1.3]
at org.apache.hive.beeline.BeeLine.main(BeeLine.java:520) [hive-beeline-3.1.3.jar:3.1.3]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_362]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_362]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_362]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_362]
at org.apache.hadoop.util.RunJar.run(RunJar.java:323) [hadoop-common-3.3.0.jar:?]
at org.apache.hadoop.util.RunJar.main(RunJar.java:236) [hadoop-common-3.3.0.jar:?]
Caused by: java.io.IOException: java.io.IOException: abfss://xxxxxx@storage.dfs.core.windows.net/user/hive/warehouse/table/part-00000-997a0587-3935-4e06-bca0-632dee826842-c000.snappy.parquet not a SequenceFile
at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextRow(FetchOperator.java:602) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.exec.FetchOperator.pushRow(FetchOperator.java:509) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.exec.FetchTask.fetch(FetchTask.java:146) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.Driver.getResults(Driver.java:2691) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.getResults(ReExecDriver.java:229) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hive.service.cli.operation.SQLOperation.getNextRowSet(SQLOperation.java:460) ~[hive-service-3.1.3.jar:3.1.3]
... 28 more
Caused by: java.io.IOException: abfss://xxxxxx@storage.dfs.core.windows.net/user/hive/warehouse/table/part-00000-997a0587-3935-4e06-bca0-632dee826842-c000.snappy.parquet not a SequenceFile
at org.apache.hadoop.io.SequenceFile$Reader.init(SequenceFile.java:1970) ~[hadoop-common-3.3.0.jar:?]
at org.apache.hadoop.io.SequenceFile$Reader.initialize(SequenceFile.java:1923) ~[hadoop-common-3.3.0.jar:?]
at org.apache.hadoop.io.SequenceFile$Reader.<init>(SequenceFile.java:1872) ~[hadoop-common-3.3.0.jar:?]
at org.apache.hadoop.io.SequenceFile$Reader.<init>(SequenceFile.java:1886) ~[hadoop-common-3.3.0.jar:?]
at org.apache.hadoop.mapred.SequenceFileRecordReader.<init>(SequenceFileRecordReader.java:49) ~[hadoop-mapreduce-client-core-3.3.0.jar:?]
at org.apache.hadoop.mapred.SequenceFileInputFormat.getRecordReader(SequenceFileInputFormat.java:64) ~[hadoop-mapreduce-client-core-3.3.0.jar:?]
at org.apache.hadoop.hive.ql.exec.FetchOperator$FetchInputFormatSplit.getRecordReader(FetchOperator.java:776) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.exec.FetchOperator.getRecordReader(FetchOperator.java:344) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextRow(FetchOperator.java:540) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.exec.FetchOperator.pushRow(FetchOperator.java:509) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.exec.FetchTask.fetch(FetchTask.java:146) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.Driver.getResults(Driver.java:2691) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.getResults(ReExecDriver.java:229) ~[hive-exec-3.1.3.jar:3.1.3]
at org.apache.hive.service.cli.operation.SQLOperation.getNextRowSet(SQLOperation.java:460) ~[hive-service-3.1.3.jar:3.1.3]
... 28 more
Error: java.io.IOException: java.io.IOException: abfss://xxxxxx@storage.dfs.core.windows.net/user/hive/warehouse/table/part-00000-997a0587-3935-4e06-bca0-632dee826842-c000.snappy.parquet not a SequenceFile (state=,code=0)以上的 HiveServer 只能說明他有成功連線到 Hive Metastore Server,要進一步去對資料做運算需要設定 hive.execution.engine 到以下等值 mr, spark, tez,預設是 mr (map reduce)。
Hive On Spark
嘗試將 hive.execution.engine 設定成 spark 並且去執行,得到以下的錯誤訊息,這說明了 HiveServer2 並沒有成功將 SQL 送到 Spark Engine 上去執行。
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://> SELECT COUNT(*) FROM table;
Query ID = root_20230503002607_da42464c-8e54-43ff-baf6-1689c33c9c9c
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create Spark client for Spark session eaf41788-060b-4eb6-bf4c-ccfef2c0d0de)'
23/05/03 00:26:12 [HiveServer2-Background-Pool: Thread-32]: ERROR spark.SparkTask: Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create Spark client for Spark session eaf41788-060b-4eb6-bf4c-ccfef2c0d0de)'
org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session eaf41788-060b-4eb6-bf4c-ccfef2c0d0de
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.getHiveException(SparkSessionImpl.java:221)
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:92)
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionManagerImpl.getSession(SparkSessionManagerImpl.java:115)
at org.apache.hadoop.hive.ql.exec.spark.SparkUtilities.getSparkSession(SparkUtilities.java:136)
at org.apache.hadoop.hive.ql.exec.spark.SparkTask.execute(SparkTask.java:115)
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:205)
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:97)
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:2664)
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:2335)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:2011)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1709)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1703)
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.run(ReExecDriver.java:157)
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:224)
at org.apache.hive.service.cli.operation.SQLOperation.access$700(SQLOperation.java:87)
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork$1.run(SQLOperation.java:316)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1845)
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork.run(SQLOperation.java:329)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
Caused by: java.lang.NoClassDefFoundError: org/apache/spark/SparkConf
at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.generateSparkConf(HiveSparkClientFactory.java:263)
at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.<init>(RemoteHiveSparkClient.java:98)
at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.createHiveSparkClient(HiveSparkClientFactory.java:76)
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:87)
... 23 more
Caused by: java.lang.ClassNotFoundException: org.apache.spark.SparkConf
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
... 27 more
23/05/03 00:26:12 [HiveServer2-Background-Pool: Thread-32]: ERROR spark.SparkTask: Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create Spark client for Spark session eaf41788-060b-4eb6-bf4c-ccfef2c0d0de)'
org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session eaf41788-060b-4eb6-bf4c-ccfef2c0d0de
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.getHiveException(SparkSessionImpl.java:221) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:92) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionManagerImpl.getSession(SparkSessionManagerImpl.java:115) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.SparkUtilities.getSparkSession(SparkUtilities.java:136) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.SparkTask.execute(SparkTask.java:115) [hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:205) [hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:97) [hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:2664) [hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:2335) [hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:2011) [hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1709) [hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1703) [hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.run(ReExecDriver.java:157) [hive-exec-3.1.2.jar:3.1.2]
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:224) [hive-service-3.1.2.jar:3.1.2]
at org.apache.hive.service.cli.operation.SQLOperation.access$700(SQLOperation.java:87) [hive-service-3.1.2.jar:3.1.2]
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork$1.run(SQLOperation.java:316) [hive-service-3.1.2.jar:3.1.2]
at java.security.AccessController.doPrivileged(Native Method) [?:1.8.0_352]
at javax.security.auth.Subject.doAs(Subject.java:422) [?:1.8.0_352]
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1845) [hadoop-common-3.3.0.jar:?]
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork.run(SQLOperation.java:329) [hive-service-3.1.2.jar:3.1.2]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [?:1.8.0_352]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_352]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_352]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_352]
at java.lang.Thread.run(Thread.java:750) [?:1.8.0_352]
Caused by: java.lang.NoClassDefFoundError: org/apache/spark/SparkConf
at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.generateSparkConf(HiveSparkClientFactory.java:263) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.<init>(RemoteHiveSparkClient.java:98) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.createHiveSparkClient(HiveSparkClientFactory.java:76) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:87) ~[hive-exec-3.1.2.jar:3.1.2]
... 23 more
Caused by: java.lang.ClassNotFoundException: org.apache.spark.SparkConf
at java.net.URLClassLoader.findClass(URLClassLoader.java:387) ~[?:1.8.0_352]
at java.lang.ClassLoader.loadClass(ClassLoader.java:418) ~[?:1.8.0_352]
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352) ~[?:1.8.0_352]
at java.lang.ClassLoader.loadClass(ClassLoader.java:351) ~[?:1.8.0_352]
at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.generateSparkConf(HiveSparkClientFactory.java:263) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.<init>(RemoteHiveSparkClient.java:98) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.createHiveSparkClient(HiveSparkClientFactory.java:76) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:87) ~[hive-exec-3.1.2.jar:3.1.2]
... 23 more
FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session eaf41788-060b-4eb6-bf4c-ccfef2c0d0de
23/05/03 00:26:12 [HiveServer2-Background-Pool: Thread-32]: ERROR ql.Driver: FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session eaf41788-060b-4eb6-bf4c-ccfef2c0d0de
23/05/03 00:26:12 [HiveServer2-Background-Pool: Thread-32]: ERROR operation.Operation: Error running hive query:
org.apache.hive.service.cli.HiveSQLException: Error while processing statement: FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session eaf41788-060b-4eb6-bf4c-ccfef2c0d0de
at org.apache.hive.service.cli.operation.Operation.toSQLException(Operation.java:335) ~[hive-service-3.1.2.jar:3.1.2]
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:226) ~[hive-service-3.1.2.jar:3.1.2]
at org.apache.hive.service.cli.operation.SQLOperation.access$700(SQLOperation.java:87) ~[hive-service-3.1.2.jar:3.1.2]
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork$1.run(SQLOperation.java:316) [hive-service-3.1.2.jar:3.1.2]
at java.security.AccessController.doPrivileged(Native Method) [?:1.8.0_352]
at javax.security.auth.Subject.doAs(Subject.java:422) [?:1.8.0_352]
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1845) [hadoop-common-3.3.0.jar:?]
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork.run(SQLOperation.java:329) [hive-service-3.1.2.jar:3.1.2]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [?:1.8.0_352]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_352]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_352]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_352]
at java.lang.Thread.run(Thread.java:750) [?:1.8.0_352]
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session eaf41788-060b-4eb6-bf4c-ccfef2c0d0de
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.getHiveException(SparkSessionImpl.java:221) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:92) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionManagerImpl.getSession(SparkSessionManagerImpl.java:115) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.SparkUtilities.getSparkSession(SparkUtilities.java:136) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.SparkTask.execute(SparkTask.java:115) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:205) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:97) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:2664) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:2335) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:2011) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1709) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1703) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.run(ReExecDriver.java:157) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:224) ~[hive-service-3.1.2.jar:3.1.2]
... 11 more
Caused by: java.lang.NoClassDefFoundError: org/apache/spark/SparkConf
at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.generateSparkConf(HiveSparkClientFactory.java:263) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.<init>(RemoteHiveSparkClient.java:98) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.createHiveSparkClient(HiveSparkClientFactory.java:76) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:87) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionManagerImpl.getSession(SparkSessionManagerImpl.java:115) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.SparkUtilities.getSparkSession(SparkUtilities.java:136) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.SparkTask.execute(SparkTask.java:115) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:205) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:97) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:2664) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:2335) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:2011) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1709) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1703) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.run(ReExecDriver.java:157) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:224) ~[hive-service-3.1.2.jar:3.1.2]
... 11 more
Caused by: java.lang.ClassNotFoundException: org.apache.spark.SparkConf
at java.net.URLClassLoader.findClass(URLClassLoader.java:387) ~[?:1.8.0_352]
at java.lang.ClassLoader.loadClass(ClassLoader.java:418) ~[?:1.8.0_352]
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352) ~[?:1.8.0_352]
at java.lang.ClassLoader.loadClass(ClassLoader.java:351) ~[?:1.8.0_352]
at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.generateSparkConf(HiveSparkClientFactory.java:263) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.<init>(RemoteHiveSparkClient.java:98) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.createHiveSparkClient(HiveSparkClientFactory.java:76) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:87) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionManagerImpl.getSession(SparkSessionManagerImpl.java:115) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.SparkUtilities.getSparkSession(SparkUtilities.java:136) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.spark.SparkTask.execute(SparkTask.java:115) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:205) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:97) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:2664) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:2335) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:2011) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1709) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1703) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.run(ReExecDriver.java:157) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:224) ~[hive-service-3.1.2.jar:3.1.2]
... 11 more
ERROR : FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session eaf41788-060b-4eb6-bf4c-ccfef2c0d0de
Error: Error while processing statement: FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session eaf41788-060b-4eb6-bf4c-ccfef2c0d0de (state=42000,code=30041)Running the Thrift JDBC/ODBC server
下一步嘗試利用 Spark Standalone 裡面的 Thrift Server 來做連線,參考官網有關 Distributed SQL Engine 的說明執行以下的指令:
./sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=<listening-port> \
--hiveconf hive.server2.thrift.bind.host=<listening-host> \
--master <master-uri>目標是想下一步可以透過以下指令,透過一個 SQL Client 去下 SQL 指令:
beeline> !connect jdbc:hive2://localhost:10000在執行之後得到以下的錯誤訊息:
root@e7233bb8500d4c69ae2f1f0760957865000000:/home/spark-current/sbin$ ./start-thriftserver.sh --hiveconf hive.server2.thrift.port=10000 --hiveconf hive.server2.thrift.bind.port=10000 --master spark://10.0.0.4:7077
starting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /home/spark-current/logs/spark--org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-e7233bb8500d4c69ae2f1f0760957865000000.out
failed to launch: nice -n 0 bash /home/spark-current/bin/spark-submit --class org.apache.spark.sql.hive.thriftserver.HiveThriftServer2 --name Thrift JDBC/ODBC Server --hiveconf hive.server2.thrift.port=10000 --hiveconf hive.server2.thrift.bind.port=10000 --master spark://10.0.0.4
SLF4J: Found binding in [jar:file:/mnt/spark-current/jars/piper-operators.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/mnt/spark-current/jars/log4j-slf4j-impl-2.17.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html$multiple_bindings for an explanation.
SLF4J: Actual binding is of type [ch.qos.logback.classic.util.ContextSelectorStaticBinder]
Error: Failed to load class org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.
Failed to load main class org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.
You need to build Spark with -Phive and -Phive-thriftserver.
23/05/03 21:49:29.795 [shutdown-hook-0] INFO o.a.spark.util.ShutdownHookManager - Shutdown hook called
23/05/03 21:49:29.797 [shutdown-hook-0] INFO o.a.spark.util.ShutdownHookManager - Deleting directory /tmp/spark-5dd56a34-24c4-41a5-9852-edbd29530e13
full log in /home/spark-current/logs/spark--org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-e7233bb8500d4c69ae2f1f0760957865000000.out這邊的錯誤訊息呈現 You need to build Spark with -Phive and -Phive-thriftserver,這的錯誤訊息的原因是因為我們使用的 spark 包並沒有 hive 與 hive-thriftserver 的 jar,解決方法是自己使用以下指令重新編譯 Spark 參考,或者是用比較簡單的方式打包成 tar 檔:
./dev/make-distribution.sh --name "with-hive-without-hadoop" --tgz "-Pyarn,hive,hive-thriftserver"這時候再重新下一樣的 start-thriftserver.sh 的指令,這時候發現有以下的錯誤訊息,不過還不是很清楚問題的根源:
23/05/05 02:25:51 ERROR StandaloneSchedulerBackend: Application has been killed. Reason: Master removed our application: FAILED
23/05/05 02:25:51 ERROR Inbox: Ignoring error
org.apache.spark.SparkException: Exiting due to error from cluster scheduler: Master removed our application: FAILED
at org.apache.spark.errors.SparkCoreErrors$.clusterSchedulerError(SparkCoreErrors.scala:218)
at org.apache.spark.scheduler.TaskSchedulerImpl.error(TaskSchedulerImpl.scala:923)
at org.apache.spark.scheduler.cluster.StandaloneSchedulerBackend.dead(StandaloneSchedulerBackend.scala:154)
at org.apache.spark.deploy.client.StandaloneAppClient$ClientEndpoint.markDead(StandaloneAppClient.scala:262)
at org.apache.spark.deploy.client.StandaloneAppClient$ClientEndpoint$anonfun$receive$1.applyOrElse(StandaloneAppClient.scala:169)
at org.apache.spark.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115)
at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:213)
at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100)
at org.apache.spark.rpc.netty.MessageLoop.org$apache$spark$rpc$netty$MessageLoop$receiveLoop(MessageLoop.scala:75)
at org.apache.spark.rpc.netty.MessageLoop$anon$1.run(MessageLoop.scala:41)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
23/05/05 02:25:51 INFO StandaloneSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
23/05/05 02:25:51 INFO SparkUI: Stopped Spark web UI at http://e7233bb8500d4c69ae2f1f0760957865000000.internal.cloudapp.net:4040
23/05/05 02:25:51 INFO StandaloneSchedulerBackend: Shutting down all executors
23/05/05 02:25:51 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down
Exception in thread "main" java.lang.IllegalStateException: Cannot call methods on a stopped SparkContext.
This stopped SparkContext was created at:
org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.main(HiveThriftServer2.scala)
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
java.lang.reflect.Method.invoke(Method.java:498)
org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$runMain(SparkSubmit.scala:958)
org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
org.apache.spark.deploy.SparkSubmit$anon$2.doSubmit(SparkSubmit.scala:1046)
org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1055)
org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
The currently active SparkContext was created at:
org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.main(HiveThriftServer2.scala)
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
java.lang.reflect.Method.invoke(Method.java:498)
org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$runMain(SparkSubmit.scala:958)
org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
org.apache.spark.deploy.SparkSubmit$anon$2.doSubmit(SparkSubmit.scala:1046)
org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1055)
org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
at org.apache.spark.SparkContext.assertNotStopped(SparkContext.scala:120)
at org.apache.spark.sql.SparkSession.<init>(SparkSession.scala:113)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:962)
at org.apache.spark.sql.hive.thriftserver.SparkSQLEnv$.init(SparkSQLEnv.scala:54)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2$.main(HiveThriftServer2.scala:96)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.main(HiveThriftServer2.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$runMain(SparkSubmit.scala:958)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$anon$2.doSubmit(SparkSubmit.scala:1046)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1055)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
23/05/05 02:25:51 INFO SparkContext: Invoking stop() from shutdown hook重新嘗試利用以下的 command 去啟動 thrift-server 就可以成功,看起來預設也是利用 port 10000,差別是連線的 endpoint 設定在 0.0.0.0:10000 而不是 localhost:10000。
root@39006d6f91bd42cf99d50378e7a0eecb000000:/home/spark-current$ ./sbin/start-thriftserver.sh --master spark://10.0.0.4:7077
root@39006d6f91bd42cf99d50378e7a0eecb000000:/home/spark-current$ ./bin/beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/mnt/spark-current/jars/log4j-slf4j-impl-2.17.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html$multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 2.3.9 by Apache Hive
beeline>
beeline> !connect jdbc:hive2://0.0.0.0:10000
Connecting to jdbc:hive2://0.0.0.0:10000
Enter username for jdbc:hive2://0.0.0.0:10000: root
Enter password for jdbc:hive2://0.0.0.0:10000: ****
08:55:29.026 INFO Utils - Supplied authorities: 0.0.0.0:10000
08:55:29.032 INFO Utils - Resolved authority: 0.0.0.0:10000
Connected to: Spark SQL (version 3.3.2)
Driver: Hive JDBC (version 2.3.9)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://0.0.0.0:10000>
0: jdbc:hive2://0.0.0.0:10000> show tables;
+------------+------------+--------------+
| namespace | tableName | isTemporary |
+------------+------------+--------------+
| default | test | false |
| default | test2 | false |
+------------+------------+--------------+
4 rows selected (1.961 seconds)
0: jdbc:hive2://0.0.0.0:10000> select count(*) from test;
+-----------+
| count(1) |
+-----------+
| 1759 |
+-----------+
1 row selected (77.111 seconds)
0: jdbc:hive2://0.0.0.0:10000> select count(*) from test2;
+-----------+
| count(1) |
+-----------+
| 1759 |
+-----------+
1 row selected (38.882 seconds)但是在下其他指令的時候會遇到以下的錯誤訊息,直覺是因為輸出的檔案量太大導致的 Hive Server2 Timeout。
0: jdbc:hive2://0.0.0.0:10000> select * from test;
org.apache.thrift.transport.TTransportException
at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:132)
at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86)
at org.apache.thrift.transport.TSaslTransport.readLength(TSaslTransport.java:374)
at org.apache.thrift.transport.TSaslTransport.readFrame(TSaslTransport.java:451)
at org.apache.thrift.transport.TSaslTransport.read(TSaslTransport.java:433)
at org.apache.thrift.transport.TSaslClientTransport.read(TSaslClientTransport.java:38)
at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86)
at org.apache.thrift.protocol.TBinaryProtocol.readAll(TBinaryProtocol.java:425)
at org.apache.thrift.protocol.TBinaryProtocol.readI32(TBinaryProtocol.java:321)
at org.apache.thrift.protocol.TBinaryProtocol.readMessageBegin(TBinaryProtocol.java:225)
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:77)
at org.apache.hive.service.rpc.thrift.TCLIService$Client.recv_FetchResults(TCLIService.java:567)
at org.apache.hive.service.rpc.thrift.TCLIService$Client.FetchResults(TCLIService.java:554)
at sun.reflect.GeneratedMethodAccessor3.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hive.jdbc.HiveConnection$SynchronizedHandler.invoke(HiveConnection.java:1524)
at com.sun.proxy.$Proxy15.FetchResults(Unknown Source)
at org.apache.hive.jdbc.HiveQueryResultSet.next(HiveQueryResultSet.java:373)
at org.apache.hive.beeline.BufferedRows.<init>(BufferedRows.java:53)
at org.apache.hive.beeline.IncrementalRowsWithNormalization.<init>(IncrementalRowsWithNormalization.java:50)
at org.apache.hive.beeline.BeeLine.print(BeeLine.java:2192)
at org.apache.hive.beeline.Commands.executeInternal(Commands.java:1009)
at org.apache.hive.beeline.Commands.execute(Commands.java:1205)
at org.apache.hive.beeline.Commands.sql(Commands.java:1134)
at org.apache.hive.beeline.BeeLine.dispatch(BeeLine.java:1314)
at org.apache.hive.beeline.BeeLine.execute(BeeLine.java:1178)
at org.apache.hive.beeline.BeeLine.begin(BeeLine.java:1033)
at org.apache.hive.beeline.BeeLine.mainWithInputRedirection(BeeLine.java:519)
at org.apache.hive.beeline.BeeLine.main(BeeLine.java:501)
Unknown HS2 problem when communicating with Thrift server.
Error: org.apache.thrift.transport.TTransportException: java.net.SocketException: Broken pipe (Write failed) (state=08S01,code=0)嘗試在起 Hive2ThriftServer 的時候加入一個 hive 的設定 (hive.spark.client.server.connect.timeout=90000),但是發生另外一個問題,原因是因為 driver 的 memory 不夠的關係,調高即可。
0: jdbc:hive2://0.0.0.0:10000> select * from test limit 500;
org.apache.thrift.TException: Error in calling method FetchResults
at org.apache.hive.jdbc.HiveConnection$SynchronizedHandler.invoke(HiveConnection.java:1532)
at com.sun.proxy.$Proxy15.FetchResults(Unknown Source)
at org.apache.hive.jdbc.HiveQueryResultSet.next(HiveQueryResultSet.java:373)
at org.apache.hive.beeline.BufferedRows.<init>(BufferedRows.java:53)
at org.apache.hive.beeline.IncrementalRowsWithNormalization.<init>(IncrementalRowsWithNormalization.java:50)
at org.apache.hive.beeline.BeeLine.print(BeeLine.java:2192)
at org.apache.hive.beeline.Commands.executeInternal(Commands.java:1009)
at org.apache.hive.beeline.Commands.execute(Commands.java:1205)
at org.apache.hive.beeline.Commands.sql(Commands.java:1134)
at org.apache.hive.beeline.BeeLine.dispatch(BeeLine.java:1314)
at org.apache.hive.beeline.BeeLine.execute(BeeLine.java:1178)
at org.apache.hive.beeline.BeeLine.begin(BeeLine.java:1033)
at org.apache.hive.beeline.BeeLine.mainWithInputRedirection(BeeLine.java:519)
at org.apache.hive.beeline.BeeLine.main(BeeLine.java:501)
Caused by: java.lang.OutOfMemoryError: Java heap space
at java.lang.StringCoding$StringDecoder.decode(StringCoding.java:149)
at java.lang.StringCoding.decode(StringCoding.java:193)
at java.lang.String.<init>(String.java:426)
at java.lang.String.<init>(String.java:491)
at org.apache.thrift.protocol.TBinaryProtocol.readStringBody(TBinaryProtocol.java:380)
at org.apache.thrift.protocol.TBinaryProtocol.readString(TBinaryProtocol.java:372)
at org.apache.hive.service.rpc.thrift.TStringColumn$TStringColumnStandardScheme.read(TStringColumn.java:453)
at org.apache.hive.service.rpc.thrift.TStringColumn$TStringColumnStandardScheme.read(TStringColumn.java:433)
at org.apache.hive.service.rpc.thrift.TStringColumn.read(TStringColumn.java:367)
at org.apache.hive.service.rpc.thrift.TColumn.standardSchemeReadValue(TColumn.java:331)
at org.apache.thrift.TUnion$TUnionStandardScheme.read(TUnion.java:224)
at org.apache.thrift.TUnion$TUnionStandardScheme.read(TUnion.java:213)
at org.apache.thrift.TUnion.read(TUnion.java:138)
at org.apache.hive.service.rpc.thrift.TRowSet$TRowSetStandardScheme.read(TRowSet.java:743)
at org.apache.hive.service.rpc.thrift.TRowSet$TRowSetStandardScheme.read(TRowSet.java:695)
at org.apache.hive.service.rpc.thrift.TRowSet.read(TRowSet.java:605)
at org.apache.hive.service.rpc.thrift.TFetchResultsResp$TFetchResultsRespStandardScheme.read(TFetchResultsResp.java:522)
at org.apache.hive.service.rpc.thrift.TFetchResultsResp$TFetchResultsRespStandardScheme.read(TFetchResultsResp.java:490)
at org.apache.hive.service.rpc.thrift.TFetchResultsResp.read(TFetchResultsResp.java:412)
at org.apache.hive.service.rpc.thrift.TCLIService$FetchResults_result$FetchResults_resultStandardScheme.read(TCLIService.java:16159)
at org.apache.hive.service.rpc.thrift.TCLIService$FetchResults_result$FetchResults_resultStandardScheme.read(TCLIService.java:16144)
at org.apache.hive.service.rpc.thrift.TCLIService$FetchResults_result.read(TCLIService.java:16091)
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:88)
at org.apache.hive.service.rpc.thrift.TCLIService$Client.recv_FetchResults(TCLIService.java:567)
at org.apache.hive.service.rpc.thrift.TCLIService$Client.FetchResults(TCLIService.java:554)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hive.jdbc.HiveConnection$SynchronizedHandler.invoke(HiveConnection.java:1524)
at com.sun.proxy.$Proxy15.FetchResults(Unknown Source)
at org.apache.hive.jdbc.HiveQueryResultSet.next(HiveQueryResultSet.java:373)
Error: org.apache.thrift.TException: Error in calling method CloseOperation (state=08S01,code=0)