[GPU] 加速主成分分析 (PCA)
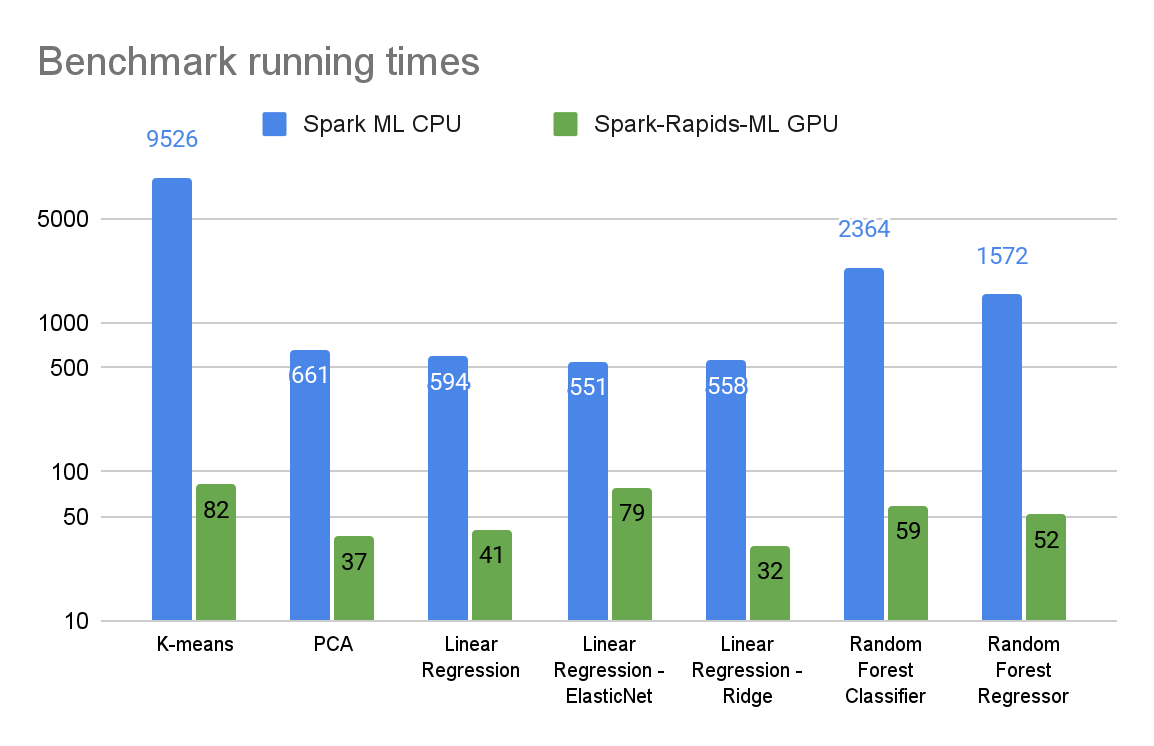
檸檬爸幾年前有分享過一篇主成分分析 (Principle Component Analysis) 原理的文章,由於 PCA 其實就是矩陣的運算,所以非常適合使用分散式運算來做加速,不論是 Spark 或是 GPU 的架構都很適合,Spark MLlib 本身就可以加速 PCA 等機器學習的運算,使用 cuML + GPU 根據 Nvidia Blog 的數據,加速的效果更加明顯,本篇想要紀錄如何導入 GPU 到 PCA 等等傳統的機器學習運算?
Spark MLlib
Spark MLlib 本身就是將 Machine Learning 的計算透過 Spark 實現,透過 pyspark.ml 裡面的 PCA 類別可以利用以下的範例將 PCA 的工作在 Spark 上執行。
>>> from pyspark.ml.linalg import Vectors
>>> data = [(Vectors.sparse(5, [(1, 1.0), (3, 7.0)]),),
... (Vectors.dense([2.0, 0.0, 3.0, 4.0, 5.0]),),
... (Vectors.dense([4.0, 0.0, 0.0, 6.0, 7.0]),)]
>>> df = spark.createDataFrame(data,["features"])
>>> pca = PCA(k=2, inputCol="features")
>>> pca.setOutputCol("pca_features")
PCA...
>>> model = pca.fit(df)
>>> model.getK()
2
>>> model.setOutputCol("output")
PCAModel...
>>> model.transform(df).collect()[0].output
DenseVector([1.648..., -4.013...])
>>> model.explainedVariance
DenseVector([0.794..., 0.205...])
>>> pcaPath = temp_path + "/pca"
>>> pca.save(pcaPath)
>>> loadedPca = PCA.load(pcaPath)
>>> loadedPca.getK() == pca.getK()
True
>>> modelPath = temp_path + "/pca-model"
>>> model.save(modelPath)
>>> loadedModel = PCAModel.load(modelPath)
>>> loadedModel.pc == model.pc
True
>>> loadedModel.explainedVariance == model.explainedVariance
True
>>> loadedModel.transform(df).take(1) == model.transform(df).take(1)
True這邊值得關注的是真正內部的實作方法還是透過 Java 的實作,pyspark 只是一個 python 的 interface,從 PCA 的類別定義 class PCA(JavaEstimator["PCAModel"], _PCAParams, JavaMLReadable["PCA"], JavaMLWritable): 我們觀察到他有繼承 JavaEstimator[“PCAModel”]
Spark Rapids ML
不同於 Spark MLlib 如果 Spark Rapids ML 在實作 PCA 的時候是呼叫自己的 PCA python 類別 from spark_rapids_ml.feature import PCA,如果我們仔細去觀察其實作的原理,就會發現它背後直接使用 cuML 的函式庫,由於 cuML 也支援從 python 驅動,所以就完美相容,以下是利用 conda 安裝 cuML 的範例:
conda create -n rapids-25.06 \
-c rapidsai -c conda-forge -c nvidia \
cuml=25.06 cuvs=25.06 python=3.10 cuda-version=11.8 numpy~=1.0完整的 python 程式碼可以參考 spark rapids examples
如果我的執行環境是 R 呢?
以上我們展示的 PCA 都是透過 Python 的程式碼實現的,如果驅動的環境是 R 的語言的話,就會是一個完全不一樣的情況,以下我們附上 SparklyR 實作的 PCA 函式,背後可以理解為直接使用 Spark MLlib。
ft_pca(
x,
input_col = NULL,
output_col = NULL,
k = NULL,
uid = random_string("pca_"),
...
)
ml_pca(x, features = tbl_vars(x), k = length(features), pc_prefix = "PC", ...)SparklyR 無法直接使用 Spark Rapids ML
由於 Spark Rapids ML 沒有支援從 SparklyR 去做驅動,所以如果要從 SparklyR 去驅動 Spark Rapids ML 感覺可以使用類似 pysparklyR 的裡面用 reticulate 的方式去驅動。