[Cloud] Azure Batch (AZTK)
隨著運算需求的增加,無可避免地要進入公有雲的領域,本篇想要整理一下 Azure 在雲端運算提供的方案但是最終專注在 Azure Batch (AZTK) 的介紹,根據 (連結) Azure 在對於 Batch 批次計算的需求大致上有幾個解決方案。
詳細內容想方涉法, France, Taiwan, Health, Information Technology
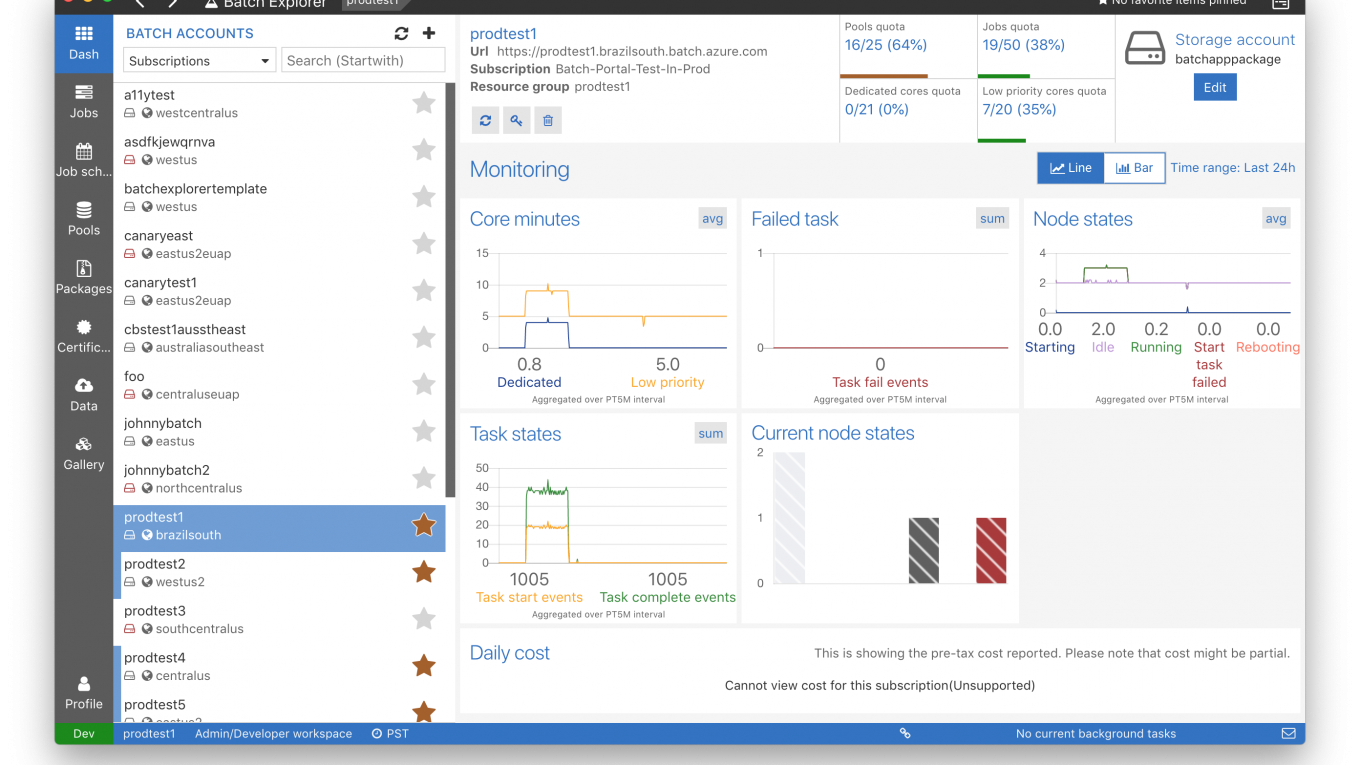
隨著運算需求的增加,無可避免地要進入公有雲的領域,本篇想要整理一下 Azure 在雲端運算提供的方案但是最終專注在 Azure Batch (AZTK) 的介紹,根據 (連結) Azure 在對於 Batch 批次計算的需求大致上有幾個解決方案。
詳細內容在前一篇文章裡面我們講解了如何針對 MySQL 資料庫中的 utf16_unicode_ci 的欄位進行讀寫,加入 utf16 的編碼的確讓開發多了很多要考慮的地方,筆者在進行網站開發的時候,為了不影響到 business 的運作,跟大部分的工程師一樣有 DEV 與 PRD 的環境,本篇想要紀錄自動拷貝 PRD 的 MySQL 資料庫到 DEV 的環境並且自動備份 utf16 MySQL Databases 的方法。
詳細內容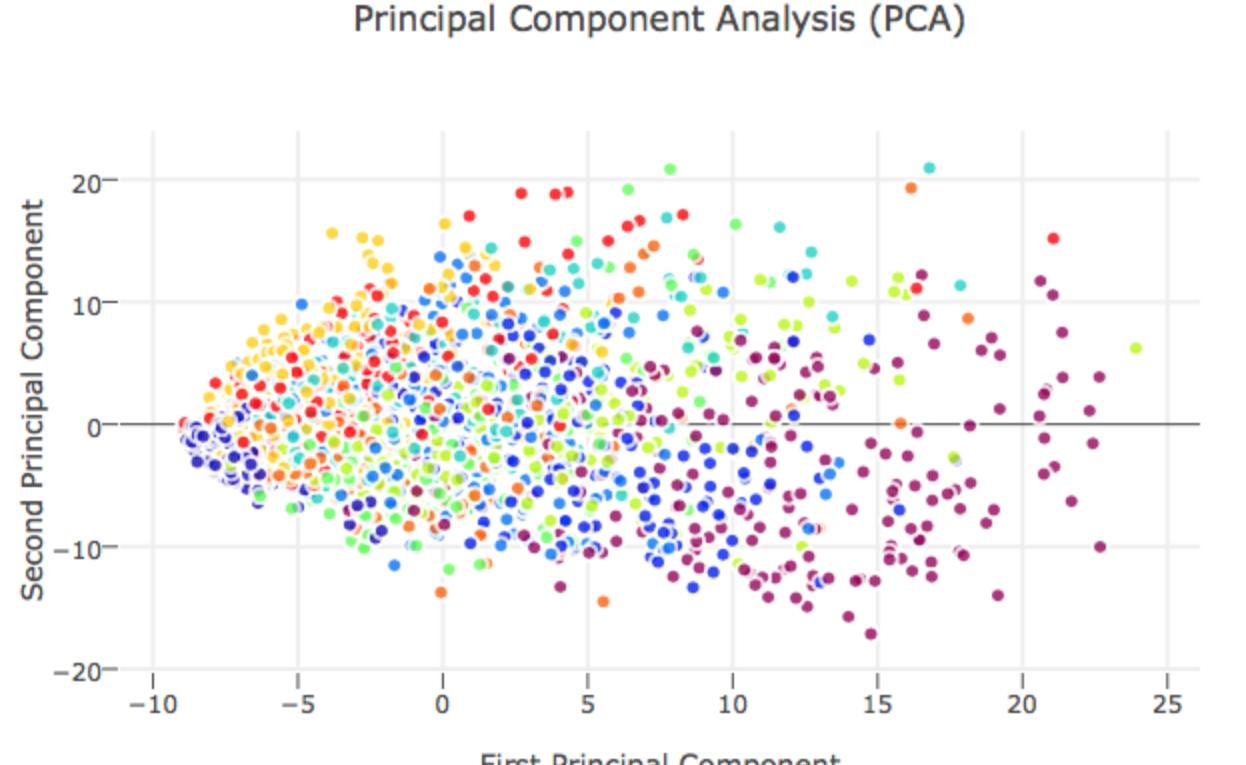
本篇想要介紹一下 Principle Component Analysis, PCA 主成份分析這一個方法背後的數學理論與物理意義,參考的是台大資工系林軒田教授的講義,在林教授的講解過程中,PCA 其實是 Auto-Encoder 中的一個線性特例,如果從 Auto-Encoder 的角度來看 PCA 的話可以更加了解 PCA 主成份分析的物理意義!
詳細內容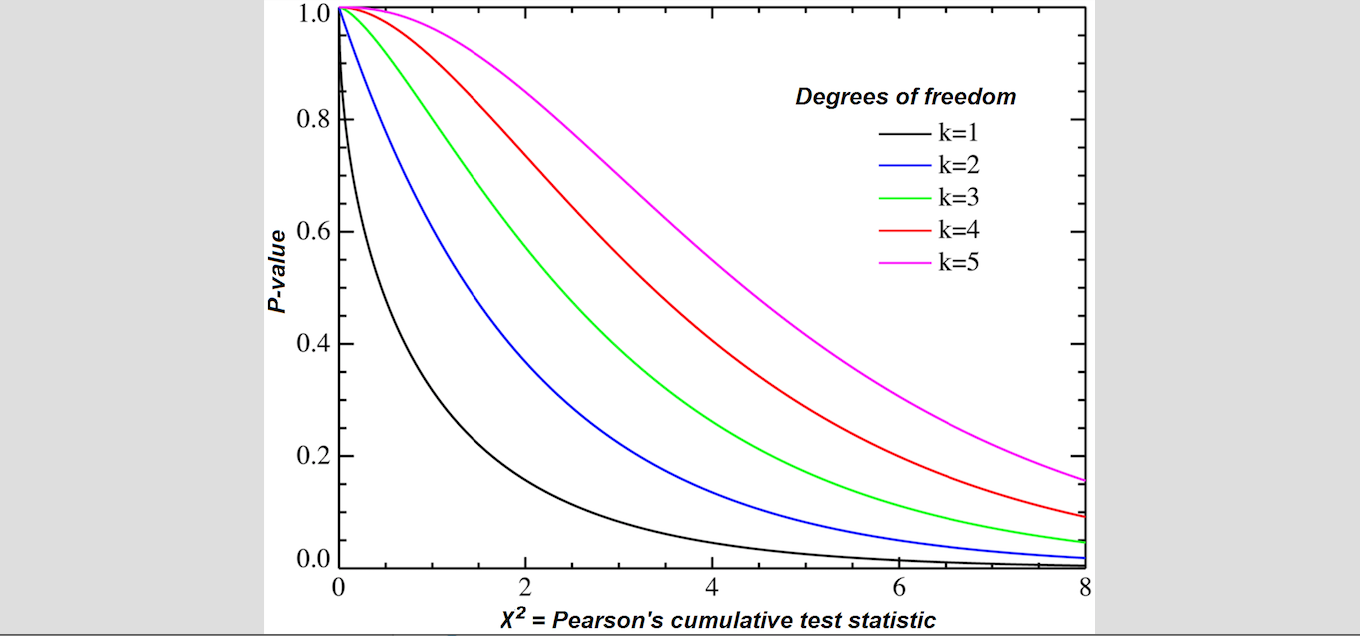
Chi-Square Test 或稱為 Chi-Squared Goodness of Fit Test 主要是透過一個樣本取樣來檢測我們是否有足夠的信心去使用 Multinomial 分佈描述這個取樣目標的隨機行為?本篇的數學推導主要參考 Michael J. Evans and Jeffrey S.Rosenthal 著作的 Probability and Statistic, The Science of Uncertainty 一書。
詳細內容
Git 是一個軟體工程師幾乎必備的工具,市面上已經有很多介紹 Git 的使用方法,本篇想要紀錄在 fork 一個專案時會需要用到的指令與使用 fork 的好處!使用 fork 的好處是可以在原本 Git 專案之外創造一個個人的遠端空間或是可以與團隊共享,在 fork 中開發的專案基本上不會影響原生的專案但是又可以寶由原本專案中的所有紀錄。
詳細內容
變數的名稱:
1. 開頭必須是字母或底線
2. 開頭不能是數字
3. 名稱只能包含字母,數字和底線
4. 字母大小寫代表的變數不同

本篇想要講述如何利用 Databricks 提供的 CLI 來針對需求下指令! 透過 Databricks-CLI 的幫助許多自動化的流程可以比較容易被實現,本篇參考的是 Azure Databricks 的官方安裝指南。
詳細內容
if…else 進階版:輸入隨機數字(用來測試之用)import random當oceane 等於 random.randint(1,10),代表oceane會隨機等於1到10其中一個數字。當oceane等於2時(要使用兩個等於記號”==”),顯示A;當oceane等於3時,顯示B;當oceane大於3時,顯示C;
詳細內容Fisher Exact Test 是一個檢驗兩個變數是否相關的方法?在基因大數據的領域裡面算是很常見的方法之一,詳細可以參考連結,由於在研讀 Fisher Exact Test 的時候,我們發現大部分網路上可以找到的訊息例如連結一,連結二都只有直接展示計算的結果但是沒有推導所以我們很難真正理解這些數學式背後的意義,本篇的推導參考 Michael J. Evans and Jeffrey S.Rosenthal 著作的 Probability and Statistic, The Science of Uncertainty 一書。
詳細內容
一般來說在視覺化資料庫的方法一般來說如果是 Hive 資料庫可以透過 DBeaver 等等類似 SQL Client 的程式來顯現,但是如果是像是 HBase 的資料庫的話基本上很難快速了解 HBase 裡面存取的檔案全貌,如果可以利用 Hive 用表格的方式呈現的話會比較好理解,本篇想要介紹如何將 HBase 利用 Hive 呈現出來!
詳細內容