[Cloud] Azure Batch (AZTK)
隨著運算需求的增加,無可避免地要進入公有雲的領域,本篇想要整理一下 Azure 在雲端運算提供的方案但是最終專注在 Azure Batch (AZTK) 的介紹,根據 (連結) Azure 在對於 Batch 批次計算的需求大致上有以下幾個解決方案:
- Azure Data Lake Analytics
- HDInsight
- Azure Databricks
- Azure Distributed Data Engineering Toolkit (AZTK) 連結
對於一開始進入 Azure 的使用者而言這還蠻複雜的,因為不了解這些的差異,最大的差異應該是 1, 2, 3 都是屬於 Dedicated Servers 費用上會比較高, 而 4 則可以使用 Low-priority Servers。AZTK 其實 Azure Batch 上的一個應用,有一點像是 Azure 的 Python API!以下是 1, 2, 3 不同解決方案的簡單比較:
| Capability | Azure Data Lake Analytics | HDInsight | Azure Databricks |
| Is managed service | Yes | Yes 可以手動更改與 scaling |
Yes |
| Relational data store | Yes | No | No |
| Pricing model | Per batch job | By cluster hour | Databricks Unit + cluster hour |
備註:Databricks 是最簡單可以在 Azure 平台上執行批次工作的服務,詳細可以參考筆者之前寫的 Databricks CLI 介紹!
以下是 Azure Batch 的相關資源整理:
Azure Batch Documentations:
關於 Azure Batch 可以觀看以下的 YouTube 連結與參考文件,
- Documentation: https://docs.microsoft.com/azure/batch/
- Code samples: https://github.com/Azure-Samples/azure-batch-samples
- Batch Explorer: https://azure.github.io/BatchExplorer
使用 Azure Batch 的 API:
想要執行一個 Spark 工作可以透過以下的方法執行:使用 Azure – CLI, 使用 Azure Portal, 使用 .NET API, 使用 Python API.
AZTK 的 API:連結
AZTK 的 API 有一點像是 Azure Batch 提供的 Python API,但是不同的是執行的工作會在 Docker 群集之上!
Azure Distributed Data Engineering Toolkit (AZTK) is a python CLI application for provisioning on-demand Spark on Docker clusters in Azure. It’s a cheap and easy way to get up and running with a Spark cluster, and a great tool for Spark users who want to experiment and start testing at scale.
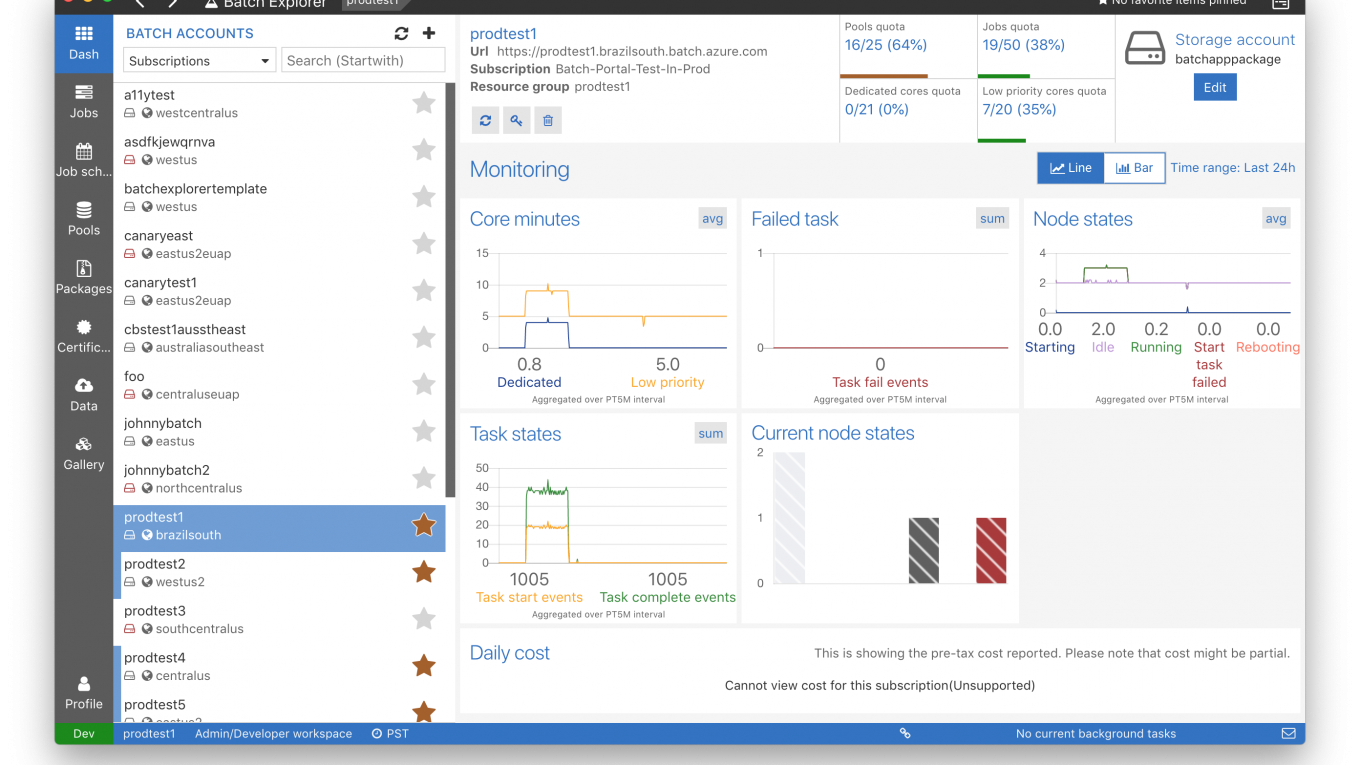
視覺化 Azure Batch + AZTK 執行的工作:
為了方便管理並且了解在 Azure 上面執行的工作狀態,可以使用 Azure Batch Explorer,透過 Azure Batch Python API 與 AZTK 執行的 Spark 工作都可以在 Batch Explorer 上面被看到!
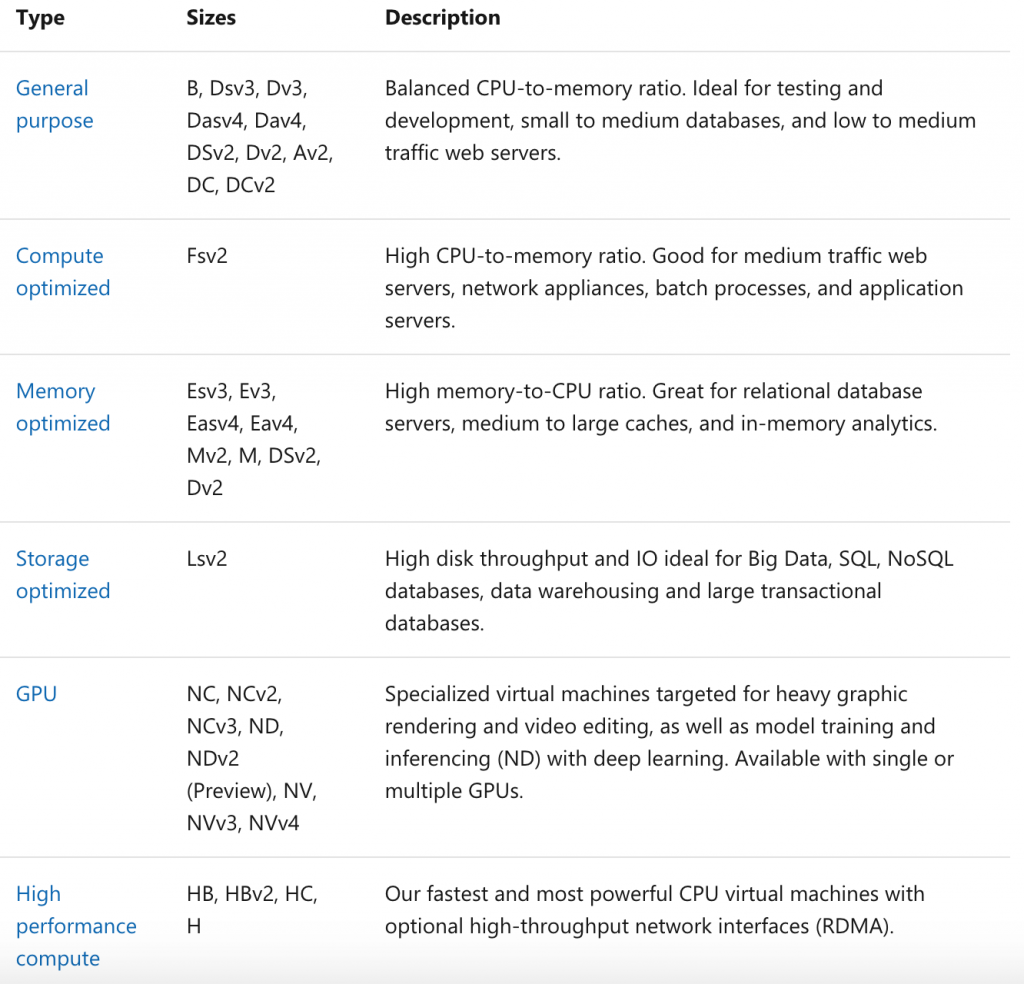
關於選擇的 Linux VM: 連結
另外值得關注的是在啟動 Azure Batch 的工作需要選擇適當與適合的虛擬機,以下是不同情況之下的虛擬機型態!