[Spark] 建置自己的 Spark History Server
進入大數據的世界,基本上脫離不了使用 Spark 這個平行運算的框架,把問題拆小之後,利用螞蟻雄兵的力量可以更容易解決問題,這也是離散數學裡面提到的 Divide and Conquer 的概念,檸檬爸之前有寫過一些介紹 Spark 的文章,也有介紹如何在 Azure 的雲端平台裡面去開啟 On Demand 的 Spark Cluster。
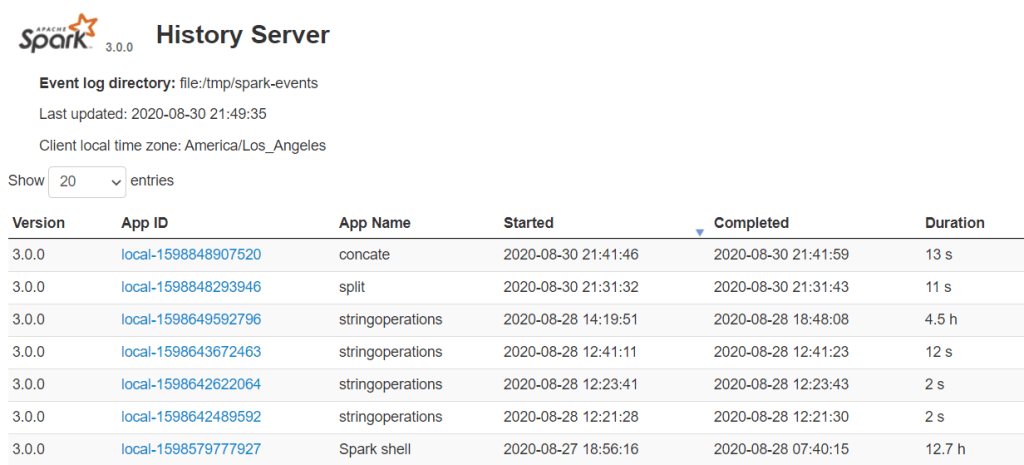
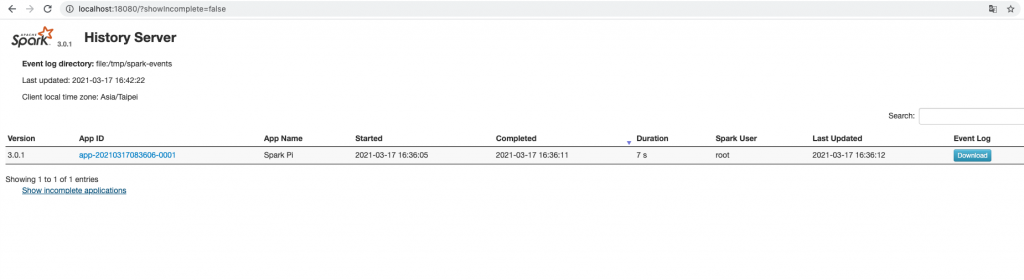
本篇要來介紹在運行 Spark Cluster 的時候一定不要忘記要開的 Spark History Server,本篇參考 aztk 的程式碼與 Spark 3.0.1 關於 Monitoring 的網頁,介紹怎麼使用 Spark History Server 。
啟動 Spark History Server
在 Spark Master 上,直接執行 $SPARK_HOME 的 shell script (start-history-server.sh),
./sbin/start-history-server.sh此時在 localhost:18080 或是 http://<server-url>:18080 就可以看到 Spark History Server 了!
Spark-Submit 的注意事項
當 Spark Cluster 與 Spark History Server 都準備好的時候,在送 spark-submit 的時候要在 spark-defaults.conf 裡面加以下三個 properties,如果想要在 local 端放 log 的話,spark.history.fs.logDirectory 與 spark.eventLog.dir 可以寫一個 local 的路徑。
spark.eventLog.enabled true
spark.history.fs.logDirectory file:/tmp/log
spark.eventLog.dir file:/tmp/log備註:
spark.history.fs.logDirectory 與 spark.eventLog.dir 也可以支援 hdfs:// 或是 s3:// 或是 abfss:// 的路徑,以下為 hdfs 的範例。
spark.eventLog.enabled true
spark.history.fs.logDirectory hdfs://namenode/shared/spark-logs
spark.eventLog.dir hdfs://namenode/shared/spark-logsAztk 關於 spark-history-server 的實作:
def start_history_server():
//configure the history server
spark_event_log_enabled_key = "spark.eventLog.enabled"
spark_event_log_directory_key = "spark.eventLog.dir"
spark_history_fs_log_directory = "spark.history.fs.logDirectory"
path_to_spark_defaults_conf = os.path.join(spark_home, "conf/spark-defaults.conf")
properties = parse_configuration_file(path_to_spark_defaults_conf)
required_keys = [spark_event_log_enabled_key, spark_event_log_directory_key, spark_history_fs_log_directory]
//only enable the history server if it was enabled in the configuration file
if properties:
if all(key in properties for key in required_keys):
configure_history_server_log_path(properties[spark_history_fs_log_directory])
exe = os.path.join(spark_home, "sbin", "start-history-server.sh")
print("Starting history server")
call([exe])