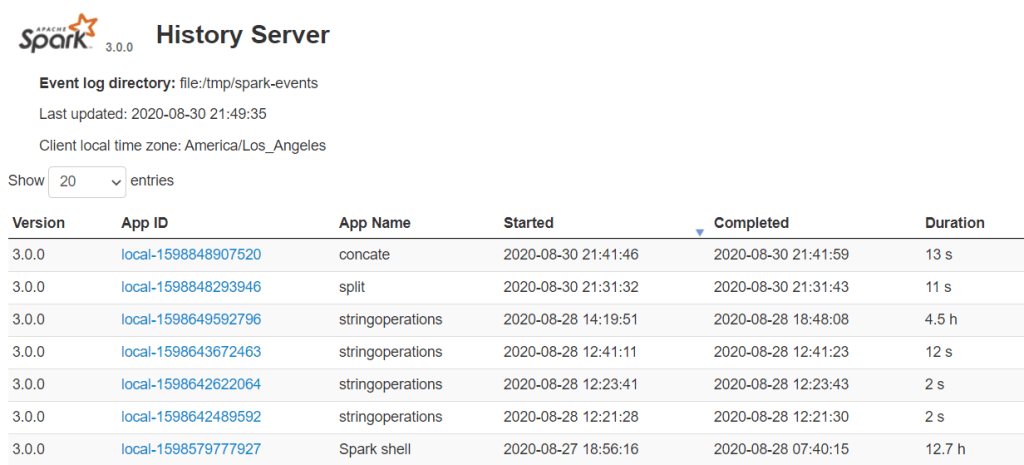
[Spark] 建置自己的 Spark History Server
進入大數據的世界,基本上脫離不了使用 Spark 這個平行運算的框架,把問題拆小之後,利用螞蟻雄兵的力量可以更容易解決問題,這也是離散數學裡面提到的 Divide and Conquer 的概念,檸檬爸之前有寫過一些介紹 Spark 的文章,也有介紹如何在 Azure 的雲端平台裡面去開啟 On Demand 的 Spark Cluster。本篇要來介紹在運行 Spark Cluster 的時候一定不要忘記要開的 Spark History Server,本篇參考 aztk 的程式碼與 Spark 3.0.1 關於 Monitoring 的網頁,介紹怎麼使用 Spark History Server 。
詳細內容