在 K8S 上簡單實現 Nvidia GPU Time-Slicing
Nvidia 的 GPU 目前是市場上使用的主流,在雲的世界裡面,由於大部分的使用場景是按需 (On Demand),因此 K8S 慢慢地也是雲端管理資源的一個利器,如何在 Kubernetes 上調用 GPU 的資源相對地也越來越普遍,本篇整理了目前網路上可以看到 Nvidia GPU 於操作方法,並且介紹一種簡單實現 GPU Time-Slicing 的設定。
詳細內容想方涉法, France, Taiwan, Health, Information Technology
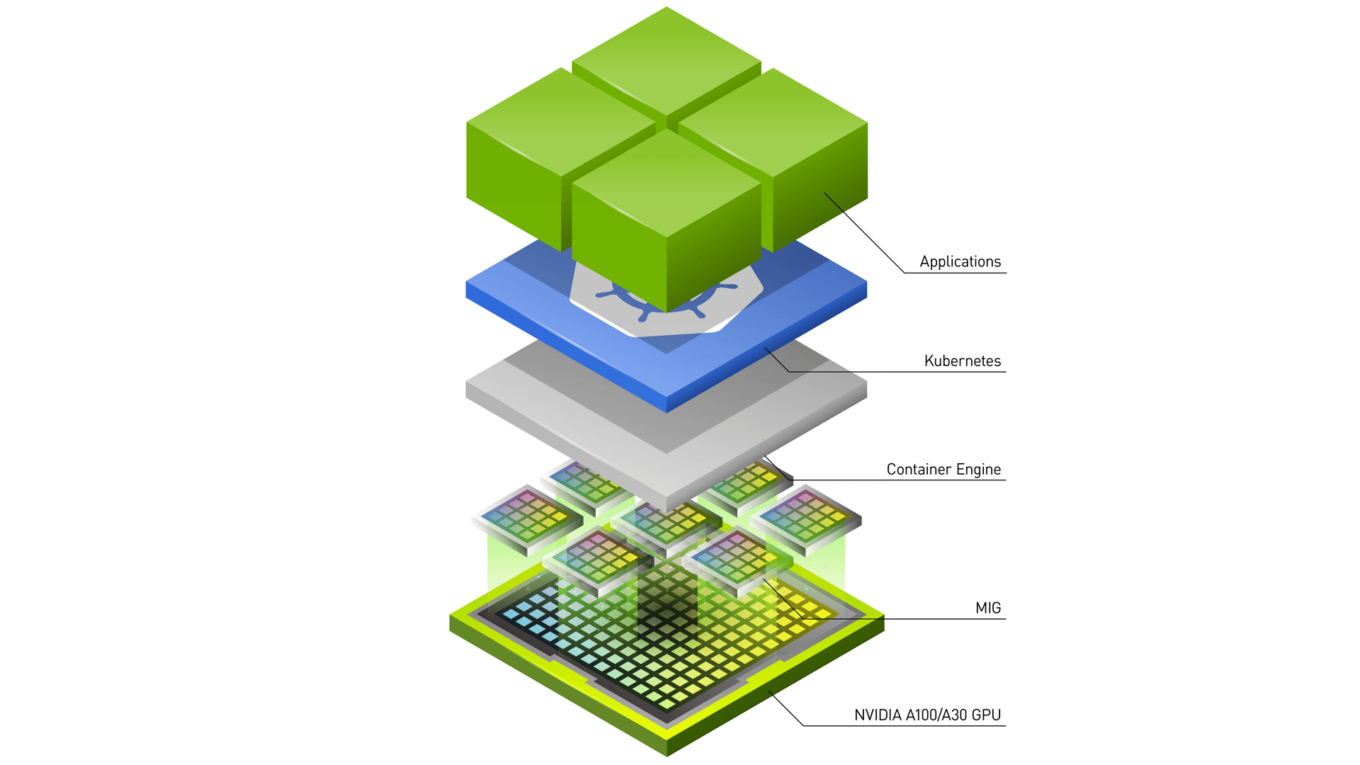
Nvidia 的 GPU 目前是市場上使用的主流,在雲的世界裡面,由於大部分的使用場景是按需 (On Demand),因此 K8S 慢慢地也是雲端管理資源的一個利器,如何在 Kubernetes 上調用 GPU 的資源相對地也越來越普遍,本篇整理了目前網路上可以看到 Nvidia GPU 於操作方法,並且介紹一種簡單實現 GPU Time-Slicing 的設定。
詳細內容
檸檬爸人生中開始使用 Apple Macbook 是在 2014 年的時候,距今也已經 10 年以上了,那時候 Macbook 的晶片架構主要是 Intel x86,一直以來都是利用 Apple 的備份工具轉換了好幾台電腦,直到去年開始使用 Apple M1 的晶片,切換到了 arm 的架構,慢慢地遇到了一些 Python 程式不能跑在 arm 架構上的問題,由於以前預設是 x86 的環境,所以自然而然 homebrew 安裝的相關程式都是 x86 的版本,例如眾多的 Python 版本,本篇紀錄如何調整 Macbook 使其能夠共存。
詳細內容
Jupyter Notebook/Lab 是一個常用的互動式介面協助各種程式碼的開發我們在上一篇『建立自己的 Jupyter Notebook 伺服器』有稍微介紹過,一般常見的使用場景是在開發 python 的程式,但是 Jupyter Server 的 Kernel 功能可以擴充更多的互動式開發環境,例如 R, PySpark, SparkR, SparklyR 等等,檸檬爸最早接觸的是將 PySpark 註冊到 Jupyter Lab 裡面,實作的程式碼是透過 AZTK 的 Repository 學習到的,後來進一步將其擴充到 R 等等的使用場景,本篇將會呈現如何部署一個有 PySpark 核心的 Jupyter Lab。
詳細內容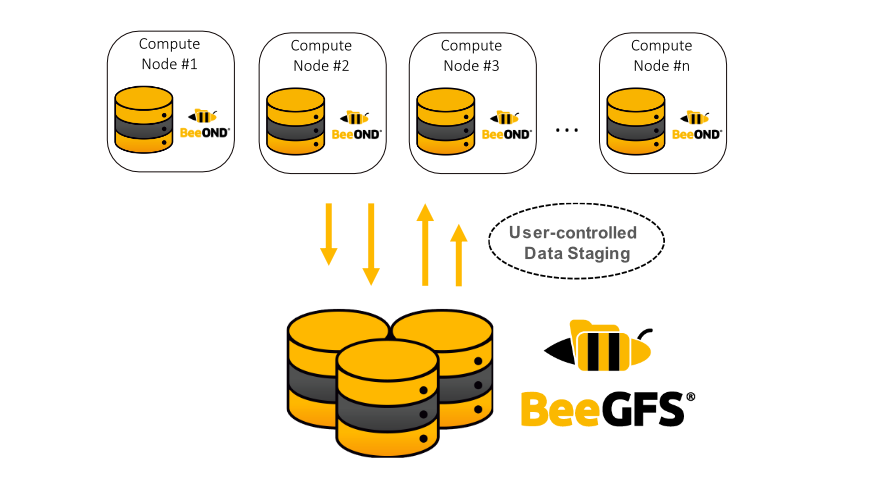
雖然公有雲的服務例如 AWS, Azure, GCP 已經逐漸普及了,但是私有雲 HPC 的市場還是一直有相對的份額,不同於公有雲的儲存服務,在佈建私有雲的時候,儲存 (Storage) 的解決方案仍然是一個需要花費大量心力的議題,本篇紀錄如何將 HPC 儲存方案之一的 BeeGFS 掛載到 K8S 的生態系裡面。
詳細內容
去接她們時,在回家的路上超開心的~ 跟我們分享今天去森林裡面玩,要穿螢光安全的背心和靴子,還有坐上馬車,讓馬帶她們走一走😆。 她們雖然覺得冷,但還好沒有感冒。回到家就開始問,明天(週四)要去哪裡上課,我們說要回學校學習,兩個馬上不想,明天還想待在 centre de loisir 😂。
詳細內容

人生去過倫敦好多趟,好像除了巴黎沒有一個國外的城市去過這麼多次,小時候跟爸爸媽媽去過英國兩次,去了 Nottingham 溫莎城堡,長大之後 2012 年跟大學同學一起看倫敦眼的跨年煙火跟音樂劇,2014 年跟家人一起遊劍橋 Cambridge,2015 年到倫敦找當時當空姐的姊姊起去了巴斯 Bath 與巨石陣 Stonehenge,2022 年參加到 Elisabeth 線開通與女王白金禧,2024 年跟太太小孩再一起去了牛津 Oxford,這次重遊時還是充滿回憶的!
詳細內容
2020 年檸檬爸有一篇介紹的 OnOff 服務的文章,在台灣可以免費接收到法國打過來的電話,不用另外付費,但是如果有需要回到法國的時候,檸檬爸建議在出發之前把同一個號碼轉回法國的某一家電信公司,如此一來就可以在一下飛機的時候馬上享受法國的電信網路,並且節省 OnOff 的費用,在本篇之前要將 OnOff 的帳號轉回法國的電信帳號都需要有一個地址重新寄送實體的 SIM 卡,但是本篇想要介紹一個新的方法,利用 eSIM 技術簡化這整個過程。
詳細內容
在導入 AWS 作為後端雲平台的時候,遇到了需要透過 curl 指令將檔案直接上傳到 S3 的需求,一開始以為一定要透過 presigned URL 的方式才能夠進行,但是後來參考了幾篇網路的文章並且經過實作驗證之後,發現也可以直接用 bash shell 配合 AWS credentials 進行,由於 AWS 的 credentials 有分成有時效性與無時效性兩種,本篇針對兩種不同的憑證放上不同的程式碼。
詳細內容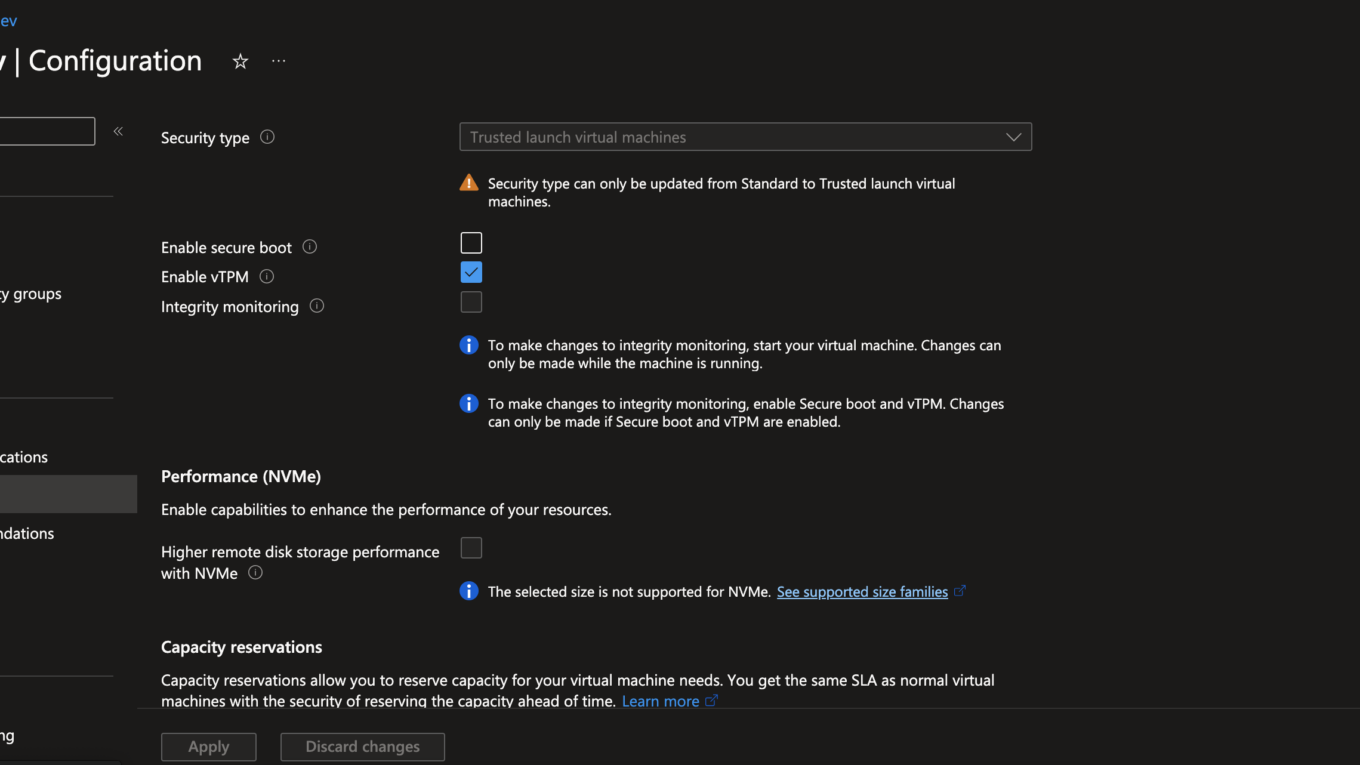
本篇想要記錄一下在 Azure Ubuntu 20.04 x64 VM 上面使用 GPU 的安裝過程,首先需要安裝相關 Nvidia GPU 的 Driver,不過究竟要安裝多少套件各方說法不一,由於之前已經有一組可以使用 GPU 的安裝指令,所以本篇以嘗試使用這組指令為基礎紀錄解決問題的方法,鳥哥的教學告訴我們可以利用 dpkg -l ‘nvidia*’ 的指令得知目前安裝所有 Nvidia GPU 相關的套件總覽,配合這個指令我們可以了解究竟安裝了什麼?
詳細內容