
[Hive/HBase] 如何串接 Hive/HBase 資料庫
一般來說在視覺化資料庫的方法一般來說如果是 Hive 資料庫可以透過 DBeaver 等等類似 SQL Client 的程式來顯現,但是如果是像是 HBase 的資料庫的話 (關於 HBase 的安裝詳情見連結),基本上很難快速了解 HBase 裡面存取的檔案全貌,假設我們有一個 HBase Table (default:status_test) 如下:
hbase(main):001> desc 'default:status_test'
Table default:status_test is ENABLED
default:status_test
COLUMN FAMILIES DESCRIPTION
{NAME => 'date', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'status', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'tablName', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
hbase(main):002> scan 'default:status_test'
ROW COLUMN+CELL
1585640055 column=date:value, timestamp=1585657858740, value=2020-03-31
1585640055 column=status:value, timestamp=1585657858740, value=DONE
1585640055 column=tableName:value, timestamp=1585657858740, value=position_snapshot
1585657560 column=date:value, timestamp=1585657531345, value=2020-03-31
1585657560 column=status:value, timestamp=1585657531345, value=531345
1585657560 column=tableName:value, timestamp=1585657531345, value=instrument_snapshot以上的方式並不是一很好呈現的方式,如果可以利用 Hive 用以下表格的方式呈現的話會比較好理解,也比較能夠讓不懂技術的人快去進入 Data 的架構!本篇想要介紹如何將 HBase 利用 Hive 呈現出來!
+------------------+-------------------------+---------------------+------------------------+--+
| status_test.key | status_test.insertdate | status_test.status | status_test.tablename |
+------------------+-------------------------+---------------------+------------------------+--+
| 1585640055 | 2020-03-31 | DONE | position_snapshot |
| 1585657460 | 2020-03-31 | DONE | instrument_snapshot |
+------------------+-------------------------+---------------------+------------------------+--+1. Hive/HBase 串接原理
Hive 跟 HBase 串接的方式是透過兩者對外的 API 互相溝通,以下是一個 Hive 與 HBase 的系統架構圖,主要是透過 hive-hbase-handler-x.x.x.jar 這一個 Java 包裝檔。
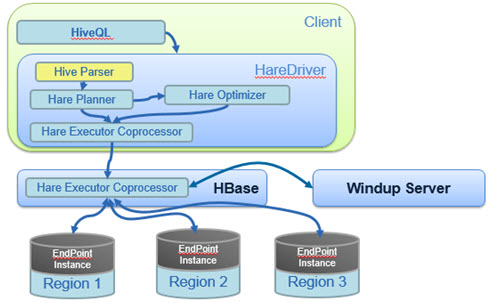
2. 實作
要新增一個 Hive 到 HBase 上面,我們可以使用以下的創建 Hive Table 的指令,以下範例主要呈現如何在 default:status_test HBase 的表格上面創建一個 Hive 的表格讓使用者下 SQL 的指令!
CREATE EXTERNAL TABLE test (key String, insertDate String, status String, tableName String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,date:value,status:value,tableName:value")
TBLPROPERTIES ("hbase.table.name" = "default:status_test",
"hbase.mapred.output.outputtable" = "default:status_test",
"hbase.struct.autogenerate" = "true");
假設 Hive Table 已經創建完成了了,我們也可以利用 Spark 技術去取得 Hive 表格裡面的資料,例如利用 Java SparkSession.sql() 等等函式。筆者在實作的時候發生以下的錯誤:
User class threw exception: java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: Error in loading storage handler.org.apache.hadoop.hive.hbase.HBaseStorageHandler
at org.apache.hadoop.hive.ql.metadata.Table.getStorageHandler(Table.java:292)
at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$getTableOption$1$$anonfun$apply$7.apply(HiveClientImpl.scala:390)
at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$getTableOption$1$$anonfun$apply$7.apply(HiveClientImpl.scala:357)
at scala.Option.map(Option.scala:146)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.hbase.HBaseStorageHandler
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)解決方法是在 pom.xml 裡面加入依賴!這也是我們在前面 Hive/HBase 串接原理講的原始碼!
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-hbase-handler</artifactId>
<version>2.1.1</version>
</dependency>如果發生以下的錯誤表示你的 HBase 裡面有經過 Avro Serialize 的二進位資料。
User class threw exception: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 3, URL, executor 2): org.apache.hadoop.hive.serde2.avro.AvroObjectInspectorException: An error occurred retrieving schema from bytes
at org.apache.hadoop.hive.serde2.avro.AvroLazyObjectInspector.retrieveSchemaFromBytes(AvroLazyObjectInspector.java:334)
at org.apache.hadoop.hive.serde2.avro.AvroLazyObjectInspector.deserializeStruct(AvroLazyObjectInspector.java:290)
at org.apache.hadoop.hive.serde2.avro.AvroLazyObjectInspector.getStructFieldDate(AvroLazyObjectInspector.java:145)
at org.apache.hadoop.hive.serde2.lazy.objectinspector.LazySimpleStructObjectInspector.getStructFieldData(LazySimpleStructObjectInspector.java:117)
at org.apache.spark.sql.hive.HadoopTableReader$$anonfun$fillObject$2.apply(TableReader.scala:438)
at org.apache.spark.sql.hive.HadoopTableReader$$anonfun$fillObject$2.apply(TableReader.scala:433)
at scala.collection.Iterator$$anon$$11.next(Iterator.scala:409)
at scala.collection.Iterator$$anon$$11.next(Iterator.scala:409)
at scala.collection.Iterator$$anon$$11.next(Iterator.scala:409)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$10$$anon$1.hasNext(WholeStageCodegenExec.scala:614)
Caused by: java.io.IOException: Not a data file.
at org.apache.avro.file.DataFileStream.initialize(DataFileStream.java:105)
at org.apache.avro.file.DataFileStream.<init>(DataFileStream.java:84)
at org.apache.hadoop.hive.serde2.avro.AvroLazyObjectInspector.retrieveSchemaFromBytes(AvroLazyObjectInspector.java:331)
.... 20 more解決方法:可以利用連結提供的方法去讀取 Avro 的內容!
備註:
雖然 Hive 可以幫助 HBase 將資料有結構的視覺化,但是要注意利用 Hive 串接 HBase 在效能上並沒有經過優化,所以會假設資料量一大的話或是執行較複雜的 SQL 指令時會佔據大量的 HBase 資源,這樣是非常危險的,會大大降低 HBase 回覆 real-time 的需求!