[ML] PCA 主成份分析
本篇想要介紹一下 Principle Component Analysis, PCA 主成份分析這一個方法背後的數學理論與物理意義,參考的是台大資工系林軒田教授的講義,在林教授的講解過程中,PCA 其實是 Auto-Encoder 中的一個線性特例,如果從 Auto-Encoder 的角度來看 PCA 的話可以更加了解 PCA 主成份分析的物理意義!
詳細內容想方涉法, France, Taiwan, Health, Information Technology
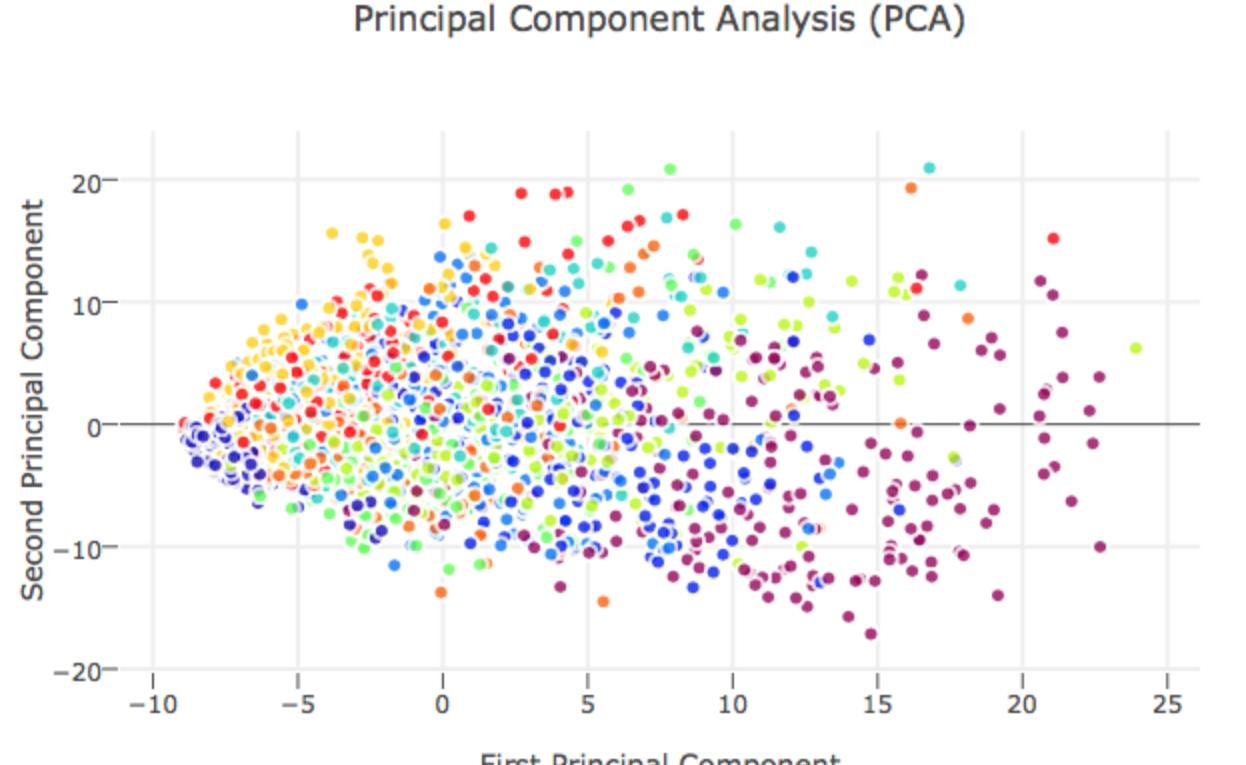
本篇想要介紹一下 Principle Component Analysis, PCA 主成份分析這一個方法背後的數學理論與物理意義,參考的是台大資工系林軒田教授的講義,在林教授的講解過程中,PCA 其實是 Auto-Encoder 中的一個線性特例,如果從 Auto-Encoder 的角度來看 PCA 的話可以更加了解 PCA 主成份分析的物理意義!
詳細內容
本篇想要講述如何利用 Databricks 提供的 CLI 來針對需求下指令! 透過 Databricks-CLI 的幫助許多自動化的流程可以比較容易被實現,本篇參考的是 Azure Databricks 的官方安裝指南。
詳細內容
一般來說在視覺化資料庫的方法一般來說如果是 Hive 資料庫可以透過 DBeaver 等等類似 SQL Client 的程式來顯現,但是如果是像是 HBase 的資料庫的話基本上很難快速了解 HBase 裡面存取的檔案全貌,如果可以利用 Hive 用表格的方式呈現的話會比較好理解,本篇想要介紹如何將 HBase 利用 Hive 呈現出來!
詳細內容在開發 Java Spark 的時候,常常會需要轉換 Dataset 或是 DataFrame,對於比較大的表格格式變換 (Schema Change),通常會使用到 JavaRDD 與 Row,開發時用到比較複雜的資料結構像是 List 或是 Map 等等的時候,有時候發生錯誤並不知道要如何除錯?本篇想要展示類別 Row: getList() 的隱藏錯誤在使用的時候發生無法理解的 NullPointerException 現象並且其解決的方法!
詳細內容Join 是一個在關聯性資料庫裡面很常使用的一個運算元,在大數據資料庫慢慢普及的今天,Join 還是一個幫助我們了解資料關係不可或缺的角色,今天想要討論的是在 Spark 裡面 Join 背後執行的運算原理,筆者在執行 Spark 工作的時候,有時候需要優化資料的運算過程以降低運算所需要的時間,本篇的資料來源可以參考連結,另外筆者也很建議大家觀看以下這一個 Youtube 影片。
詳細內容
本篇想要持續記錄在執行 Spark, Hadoop 開發的時候所遇到的所有問題,並提供相對應的參考資料,提供一個第三方的看法當開發者在遇到類似問題的時候可以有靈感可以解決!
詳細內容
這一篇想要紀錄的是在訓練 YOLO 即時影像辨識系統會用到的標記技術 LabelImg,這一篇主要是紀錄並且協助檸檬爸釐清如何安裝 LabelImg 程式。圖像標記的程式可以下載 LabelImg (https://github.com/tzutalin/labelImg) ,裡面有安裝的說明,本篇使用的是 Mac+VirtualEnv 的安裝方法。
詳細內容在開始做大數據的專案的時候通常都會遇到這個問題,要先把資料送到 Hdfs 上之後,資料才有可能被 Spark 等程式使用,一般來說傳送檔案到 Hdfs 可以利用以下方法,EMS/RabbitMQ, Knox Server, FTR 或是 Kafka 等等,常見的做法是透過 Knox 伺服器,由於 Hdfs 的群集是由多個 NameNode 與多個 DataNode 組成,最直接的做法是產生一個 FileSystem 直接指向 Hdfs 而不是透過 Knox,本篇要呈現如何不透過 Knox 向 Hdfs 傳送資料!
詳細內容
當我們下指令詢問 Hive 的資料庫的時候,在比較進階的情況中,常常會遇到一些複雜的資料結構(struct),例如 array, map, array
在開發 Spark 大數據程式的時候,基本上都會遇到測試的需求,但是可能當時並沒有建立相對應的服務 Cluster 例如 Hdfs, Hive, HBase 等等的資料庫,所以在開發上面會遇到很多困難,其實 Hdfs 還算是比較好解決的,使用 FileSystem 某種程度上面還是可以利用本機的磁碟模擬 Hdfs測試其 Java 程式與 Hdfs 的溝通情況,但是如果遇到像是 Hive, HBase 等等的資料庫,在沒有真正群集的情況之下如何測試自己的程式就變得非常需要了!本篇要介紹的是一個第三方函式庫可以幫助我們單元測試 Java 的程式:
詳細內容