[Rapids] Enable GPU on Spark
最近在學習有關 Spark 跑在 GPU 上面的新技術 (Rapid) 本篇記錄一些有用的學習資源,最直接的就是看 Rapids 的 Github。但是直接看 Code 的缺點就是一下子太多資訊,所以如果能夠配合著一些概念性的影片介紹就能夠很快的了解 Rapids 的架構。
詳細內容想方涉法, France, Taiwan, Health, Information Technology

最近在學習有關 Spark 跑在 GPU 上面的新技術 (Rapid) 本篇記錄一些有用的學習資源,最直接的就是看 Rapids 的 Github。但是直接看 Code 的缺點就是一下子太多資訊,所以如果能夠配合著一些概念性的影片介紹就能夠很快的了解 Rapids 的架構。
詳細內容檸檬爸在開發 Spark, Java, Scala 程式的時候很常遇到 NoSuchMethodError/ClassNotFound 這兩個錯誤,通常出現這兩個錯誤訊息的時候,主要原因是因為 Java Package 的 Dependency Conflict,在開發 Spark 的應用的時候究竟要怎麽去處理會比較好?本篇想要紀錄幾個常用的解法,包含Java 指令, JD-GUI 與 Maven Dependency:Tree 的介紹。
詳細內容
使用 Spark/Hadoop 生態系這麼久之後,最近才開始來研究 Hadoop 的 checksum 機制是怎麼運作的?
詳細內容
最近在研究如何在 K8S 上面跑一個 On-Demand 的 Spark Cluster 服務,基本上有兩條路可以走,一條是利用 k8s 的 Deployment 來自建 Spark Cluster,另外一條路則是利用 Kubernetes 既有與 Spark 對接的介面 (這邊是利用 spark-submit) 來實作,概念上就是直接執行一個類似下方的指令,所以想要擁有一個 On-Demand Spark Cluster on AKS 這兩種方法個有什麼優劣?
詳細內容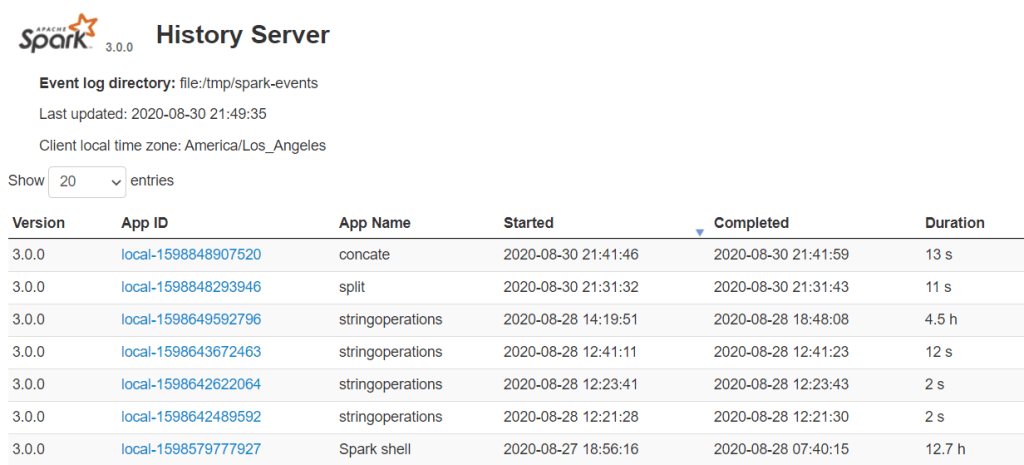
進入大數據的世界,基本上脫離不了使用 Spark 這個平行運算的框架,把問題拆小之後,利用螞蟻雄兵的力量可以更容易解決問題,這也是離散數學裡面提到的 Divide and Conquer 的概念,檸檬爸之前有寫過一些介紹 Spark 的文章,也有介紹如何在 Azure 的雲端平台裡面去開啟 On Demand 的 Spark Cluster。本篇要來介紹在運行 Spark Cluster 的時候一定不要忘記要開的 Spark History Server,本篇參考 aztk 的程式碼與 Spark 3.0.1 關於 Monitoring 的網頁,介紹怎麼使用 Spark History Server 。
詳細內容在上一篇我們探討了 Hdfs 在 Hadoop 3.1.2 的時候要怎麼安裝?最近由於筆者需要將 Spark 2.4 升到 Spark 3.0 以上,所以順便研究並且探討 Hadoop 3.x 與 Hadoop 2.x 版本的差異,本篇主要參考的是 Data Flair 網站上面的比較差異,我們整理並且精簡 22 項差異中到最重要的 7 項。
詳細內容
因緣際會之下開始使用 Google Storage 的服務,所以想說要用一篇文章記錄,由於 Google Cloud 的服務五花八門非常多樣化,所以這邊主要會專注在介紹 Google Storage,包含安裝與一些簡單的操作。
詳細內容Apache Spark 是一個平行運算的運算平台,由於他在處理不同檔案格式都有強大的資源庫支援,所以如果 leverage 來進行一些資料處理的開發很合適,另外 Spark 可以使用 local 或是 yarn 模式,使用 local 模式開發的進入障礙不會很大,本篇說明如何安裝 Spark 到遠端伺服器上面,部署並執行 spark 的程式!
詳細內容在上一篇我們介紹了 Azure 提供的雲端運算資源,例如 Databricks, HDInsight, Azure Batch 等等,利用 AZTK 可以快速部署一個運算的群集,用戶可以指定 Dedicated Nodes 的數量和 Low Priority Nodes 的數量,本篇想要介紹 Azure Batch Auto Scaling 的功能以及如何使用,詳細可以參考以下文章。
詳細內容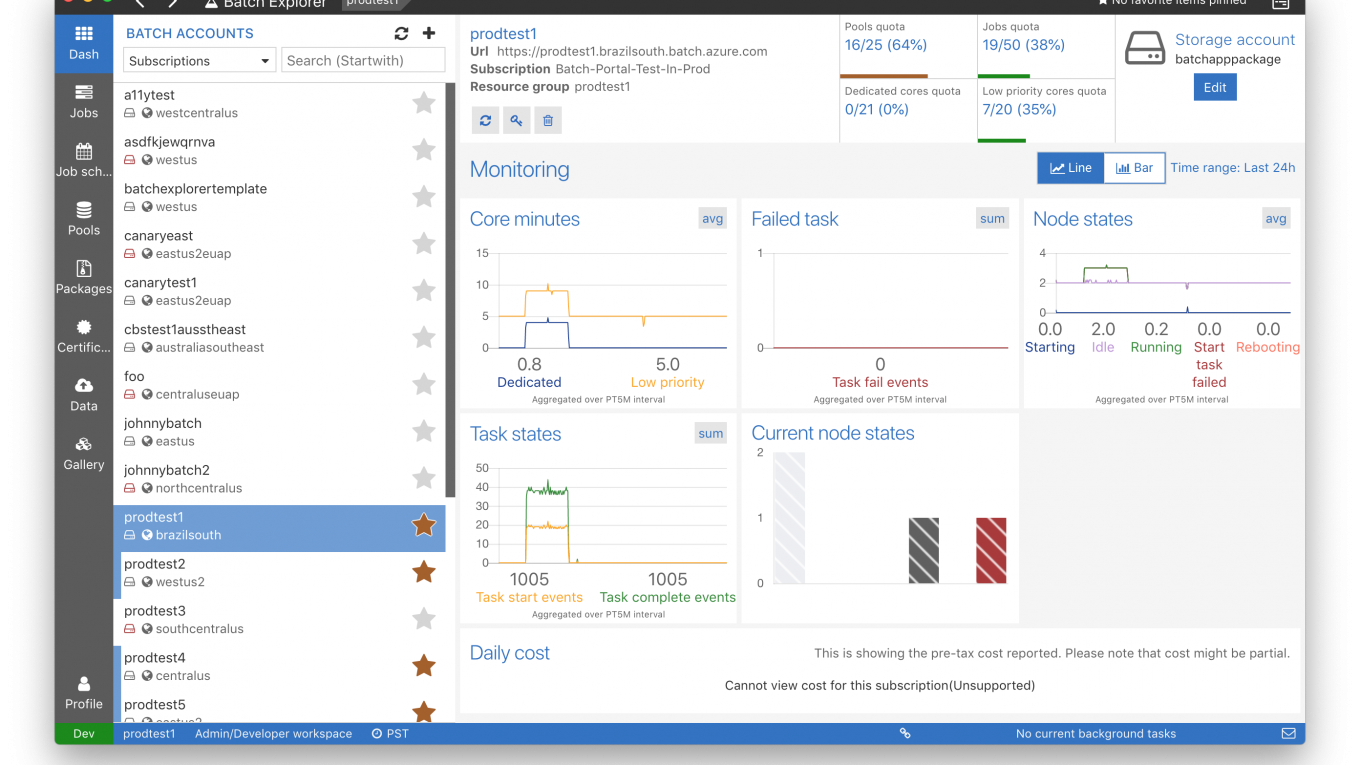
隨著運算需求的增加,無可避免地要進入公有雲的領域,本篇想要整理一下 Azure 在雲端運算提供的方案但是最終專注在 Azure Batch (AZTK) 的介紹,根據 (連結) Azure 在對於 Batch 批次計算的需求大致上有幾個解決方案。
詳細內容