
[Spark] Define and Register Hive UDF with Spark Rapids
在上一篇我們介紹如何透過 Spark Rapids 去利用 GPU 加速執行 SQL,我們遇到了幾個問題並一一解決,最後我們成功在 Spark Thrift Server 上面啟動了 Spark Rapids 的功能,並且使用 pyHive 將 SQL 的 Request 送進 Spark Cluster 裡面,為了要更進一步完全使用 GPU 的資源,在執行 SQL command 的時候如果遇到沒有支援 Spark Rapids 的 UDF (User-Defined Function) 的時候,會拖慢整體的速度,讓使用 GPU 的效果沒有發揮出來,因此本篇想要紀錄如何實作並定義一個 Hive UDF。
實作 Hive UDF 範例
Simple Tutorial: Building a Hive User Defined Function
這一篇文章提供了一個範例實作 Hive UDF: Structured data in Hive: a generic UDF to sort arrays of structs
package com.congiu.udf;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde.Constants;
import org.apache.hadoop.hive.serde2.objectinspector.ListObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import static org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector.Category.LIST;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorUtils;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
/**
*
* @author rcongiu
*/
@Description(name = "array_struct_sort",
value = "_FUNC_(array(struct1,struct2,...), string myfield) - " +
"returns the passed array struct, ordered by the given field ",
extended = "Example:\n" +
" > SELECT _FUNC_(str, 'myfield') FROM src LIMIT 1;\n" +
" 'b' ")
public class ArrayStructSortUDF extends GenericUDF {
protected ObjectInspector[] argumentOIs;
ListObjectInspector loi;
StructObjectInspector elOi;
// cache comparators for performance
Map < String, Comparator > comparatorCache = new HashMap < String, Comparator > ();
@Override
public ObjectInspector initialize(ObjectInspector[] ois) throws UDFArgumentException {
// all common initialization
argumentOIs = ois;
// clear comparator cache from previous invokations
comparatorCache.clear();
return checkAndReadObjectInspectors(ois);
}
/**
* Utility method to check that an object inspector is of the correct type,
* and returns its element object inspector
* @param oi
* @return
* @throws UDFArgumentTypeException
*/
protected ListObjectInspector checkAndReadObjectInspectors(ObjectInspector[] ois)
throws UDFArgumentTypeException, UDFArgumentException {
// check number of arguments. We only accept two,
// the list of struct to sort and the name of the struct field
// to sort by
if (ois.length != 2) {
throw new UDFArgumentException("2 arguments needed, found " + ois.length);
}
// first argument must be a list/array
if (!ois[0].getCategory().equals(LIST)) {
throw new UDFArgumentTypeException(0, "Argument 1" +
" of function " + this.getClass().getCanonicalName() + " must be " + Constants.LIST_TYPE_NAME +
", but " + ois[0].getTypeName() +
" was found.");
}
// a list/array is read by a LIST object inspector
loi = (ListObjectInspector) ois[0];
// a list has an element type associated to it
// elements must be structs for this UDF
if (loi.getListElementObjectInspector().getCategory() != ObjectInspector.Category.STRUCT) {
throw new UDFArgumentTypeException(0, "Argument 1" +
" of function " + this.getClass().getCanonicalName() + " must be an array of structs " +
" but is an array of " + loi.getListElementObjectInspector().getCategory().name());
}
// store the object inspector for the elements
elOi = (StructObjectInspector) loi.getListElementObjectInspector();
// returns the same object inspector
return loi;
}
// to sort a list , we must supply our comparator
public class StructFieldComparator implements Comparator {
StructField field;
public StructFieldComparator(String fieldName) {
field = elOi.getStructFieldRef(fieldName);
}
public int compare(Object o1, Object o2) {
// ok..so both not null
Object f1 = elOi.getStructFieldData(o1, field);
Object f2 = elOi.getStructFieldData(o2, field);
// compare using hive's utility functions
return ObjectInspectorUtils.compare(f1, field.getFieldObjectInspector(),
f2, field.getFieldObjectInspector());
}
}
// factory method for cached comparators
Comparator getComparator(String field) {
if (!comparatorCache.containsKey(field)) {
comparatorCache.put(field, new StructFieldComparator(field));
}
return comparatorCache.get(field);
}
@Override
public Object evaluate(DeferredObject[] dos) throws HiveException {
// get list
if (dos == null || dos.length != 2) {
throw new HiveException("received " + (dos == null ? "null" :
Integer.toString(dos.length) + " elements instead of 2"));
}
// each object is supposed to be a struct
// we make a shallow copy of the list. We don't want to sort
// the list in place since the object could be used elsewhere in the
// hive query
ArrayList al = new ArrayList(loi.getList(dos[0].get()));
// sort with our comparator, then return
// note that we could get a different field to sort by for every
// invocation
Collections.sort(al, getComparator((String) dos[1].get()));
return al;
}
@Override
public String getDisplayString(String[] children) {
return (children == null ? null : this.getClass().getCanonicalName() + "(" + children[0] + "," + children[1] + ")");
}
}實作 RAPIDS Accelerated User Defined Functions
實作完以上的 Hive UDF,我們只是能成功在 Spark Thrift Server 上執行自定義的 UDF,此時這個 UDF 並沒有辦法被搬到 GPU 去執行,因此我們還需要再繼續將這個 class 繼承到 RapidsUDF 並且實作 evaluateColumnar 這一個函數,讀者有興趣可以進一步去參考 Spark Rapids 的 Tutorial ,他們展示了四個範例,分別是 DecimalFraction, StringWordCount, URLDecode 和 URLEncode,以下我們直接呈現 DecimalFraction:
/*
* Copyright (c) 2021-2022, NVIDIA CORPORATION.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.nvidia.spark.rapids.udf.hive;
import ai.rapids.cudf.ColumnVector;
import ai.rapids.cudf.Scalar;
import com.nvidia.spark.RapidsUDF;
import org.apache.hadoop.hive.common.type.HiveDecimal;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.io.HiveDecimalWritable;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.typeinfo.DecimalTypeInfo;
import java.math.BigDecimal;
/**
* A simple HiveGenericUDF demo for DecimalType, which extracts and returns
* the fraction part of the input Decimal data. So, the output data has the
* same precision and scale as the input one.
*/
public class DecimalFraction extends GenericUDF implements RapidsUDF {
private transient PrimitiveObjectInspector inputOI;
@Override
public String getDisplayString(String[] strings) {
return getStandardDisplayString("DecimalFraction", strings);
}
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length != 1) {
throw new UDFArgumentException("One argument is supported, found: " + arguments.length);
}
if (!(arguments[0] instanceof PrimitiveObjectInspector)) {
throw new UDFArgumentException("Unsupported argument type: " + arguments[0].getTypeName());
}
inputOI = (PrimitiveObjectInspector) arguments[0];
if (inputOI.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.DECIMAL) {
throw new UDFArgumentException("Unsupported primitive type: " + inputOI.getPrimitiveCategory());
}
DecimalTypeInfo inputTypeInfo = (DecimalTypeInfo) inputOI.getTypeInfo();
return PrimitiveObjectInspectorFactory.getPrimitiveWritableObjectInspector(inputTypeInfo);
}
@Override
public Object evaluate(GenericUDF.DeferredObject[] arguments) throws HiveException {
if (arguments[0] == null || arguments[0].get() == null) {
return null;
}
Object input = arguments[0].get();
HiveDecimalWritable decimalWritable = (HiveDecimalWritable) inputOI.getPrimitiveWritableObject(input);
BigDecimal decimalInput = decimalWritable.getHiveDecimal().bigDecimalValue();
BigDecimal decimalResult = decimalInput.subtract(new BigDecimal(decimalInput.toBigInteger()));
HiveDecimalWritable result = new HiveDecimalWritable(decimalWritable);
result.set(HiveDecimal.create(decimalResult));
return result;
}
@Override
public ColumnVector evaluateColumnar(int numRows, ColumnVector... args) {
if (args.length != 1) {
throw new IllegalArgumentException("Unexpected argument count: " + args.length);
}
ColumnVector input = args[0];
if (numRows != input.getRowCount()) {
throw new IllegalArgumentException("Expected " + numRows + " rows, received " + input.getRowCount());
}
if (!input.getType().isDecimalType()) {
throw new IllegalArgumentException("Argument type is not a decimal column: " +
input.getType());
}
try (Scalar nullScalar = Scalar.fromNull(input.getType());
ColumnVector nullPredicate = input.isNull();
ColumnVector integral = input.floor();
ColumnVector fraction = input.sub(integral, input.getType())) {
return nullPredicate.ifElse(nullScalar, fraction);
}
}
}基本上在 evaluateColumnar 函式裡面我們要做的事情就是把 ColumnVector 這個物件透過 Nvidia 提供的函式參考連結 (https://docs.rapids.ai/api/cudf-java/stable/ai/rapids/cudf/columnview) 去轉換成另外一個 ColumnVector 然後回傳,基本上這些 function 都是利用 JNI 匯入到 JAVA 的 C++ 程式碼,如此一來 SparkRapids 就可以透過 Java 去調用底層的 CUDA 程式,下圖(參考2020 Spark-Submit 的投影片)是整個 Rapids 的技術 ETL。
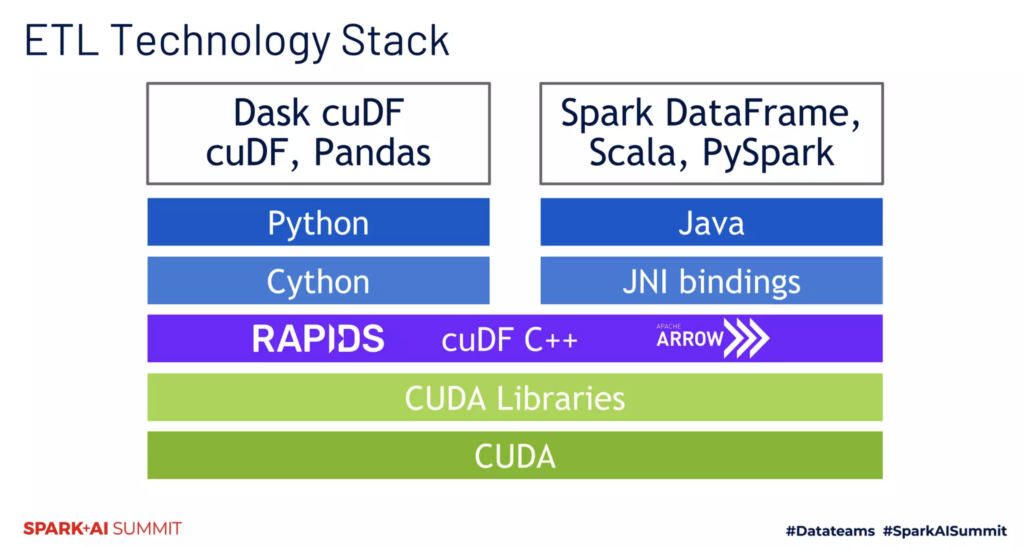
由於 Nvidia 提供的 ColumnView 轉換的程式終究是有限,所以如果用戶有更客製化的需求的話,需要更進一步利用 cuDF C++ 去撰寫自己需要的程式碼,以下我們列出 Nvidia 已經有的 JNI Java 函式對應的 C++ 程式碼在以下的連結裡面作為參考。
cuDF 實作的 ColumnViewJni
https://github.com/rapidsai/cudf/blob/branch-24.02/java/src/main/native/src/ColumnViewJni.cpp
表列所有已經存在的 Functions
SHOW FUNCTIONS註冊 UDF 進 Hive Metastore 參考 Managing Apache Hive User-defined Functions
CREATE FUNCTION <function_name> AS '<fully_qualified_class_name>' USING JAR 'hdfs:///<path/to/jar/in/hdfs>'從 Hive Metastore 中清除已有的 UDF
DROP FUNCTION <function_name>
Good luck 🙂
Good luck 🙂