[ML] Fine Tune Spark NLP QA model
使用 Spark NLP 去執行 Question Answering 的範例,可以參考 JohnSnowLabs 裡面很多的 Question Answering 模型,例如 Roberta QA Model,至於要怎麼去 Fine Tune QA 模型?在 Spark NLP 裡面並沒有講解得很清楚,本篇想要記錄如何 Fine Tune 一個自己的 QA 模型供 Spark NLP 來使用?
詳細內容想方涉法, France, Taiwan, Health, Information Technology

使用 Spark NLP 去執行 Question Answering 的範例,可以參考 JohnSnowLabs 裡面很多的 Question Answering 模型,例如 Roberta QA Model,至於要怎麼去 Fine Tune QA 模型?在 Spark NLP 裡面並沒有講解得很清楚,本篇想要記錄如何 Fine Tune 一個自己的 QA 模型供 Spark NLP 來使用?
詳細內容
本篇想要記錄在實作安裝 Apache Superset 並且配合後端 HIVE 的資料庫進行資料呈現,一開始以為是要在 superset_config.py 內部設定SQLALCHEMY_DATABASE_URI 到指定的 Hive Server,後來了解到那是 Superset 內部 Database, Dataset 與 Charts 設定的儲存位置,本篇參考 Apache Superset 的網站實作安裝 Superset,希望對讀者有所幫助。
詳細內容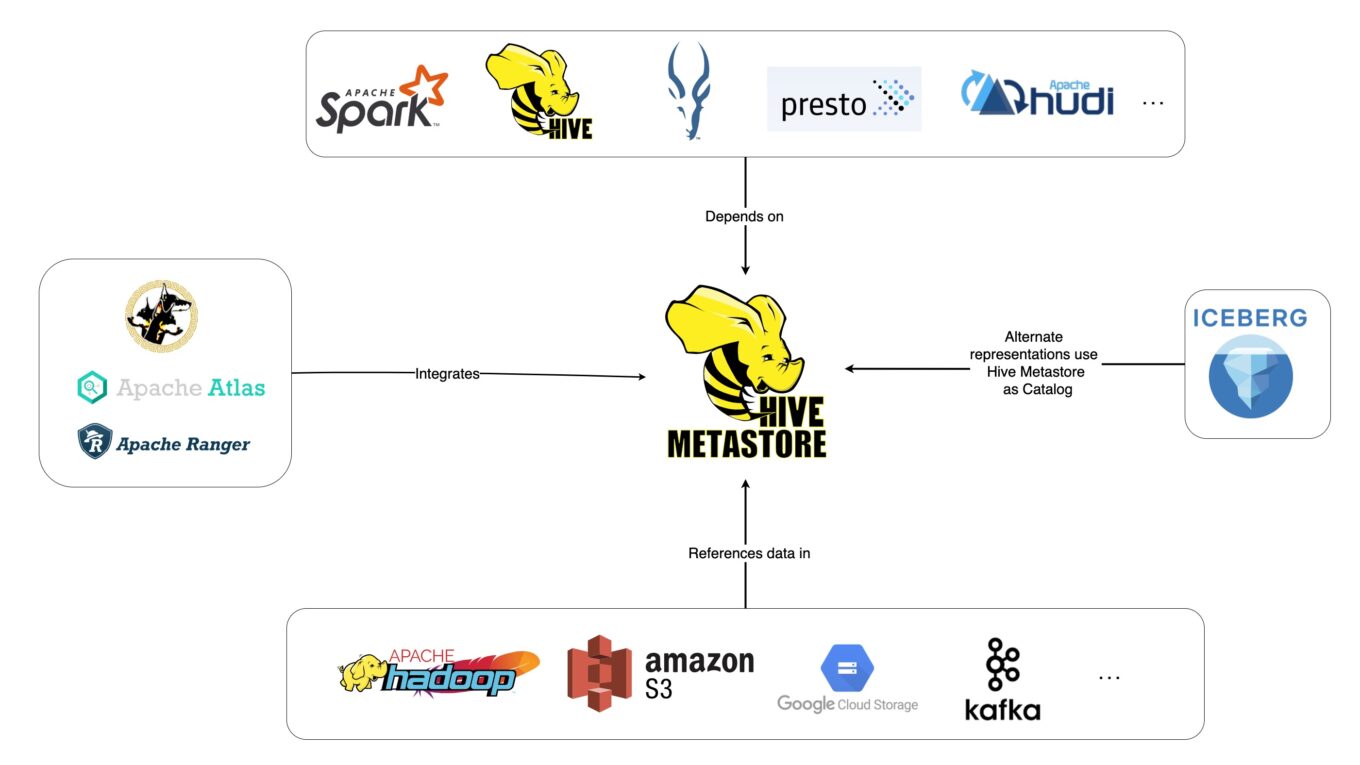
在上一篇我們介紹了如何利用 MySQL 服務建立屬於自己的 Hive Metastore 資料庫,並且利用 Spark SQL 的方式對 Metastore 裡面的資料做存取,根據上方圖示,我們可以理解除了 Spark 可以對 Hive Metastore 做存儲之外,我們也可以利用 Hive, Impala, Presto, Apache Hudi 甚至是最近出來的 Apache Superset 來做資料串接,本篇想要紀錄並且比較這幾種技術的優缺點是什麼?
詳細內容
最近需要用到 VPN,因為某些網站有擋台灣的 IP,所以有需要遠端桌面的需求,Microsoft Azure 的 VM 可以開在世界不同的資料中心裡面,本篇紀錄一下實作在 Azure 上開出一台 Ubuntu 的 VM 安裝遠端桌面伺服器,然後利用 Microsoft Remote Desktop 遠端登入進去操作,實作方法參考的是技術文件 Install and configure xrdp to use Remote Desktop with Ubuntu。
詳細內容
Django 是一個以 Python 為基底開發網站服務的框架,近年來越來越多開發人員使用 Python 語言,所以要切入網站或者是 API 的開發,Django 會是一個很好的選擇,之前檸檬爸初學 Django 寫過一篇初淺的介紹文,後來,真正在進入 Production 階段的時候遇到一些問題,本篇紀錄在部署 Django 到 Apache Server 上的時候遇到的挑戰。
詳細內容
擁有一個自己的 Hive Metastore 的好處是方便管理自己的資料,利用 Hive Metastore 可以把資料表與大數據平台上面的資料關連起來。Hive Metastore 可以部署在不同的資料庫上面,例如 MySQL 或是 Microsoft SQL Database。
詳細內容
在開發 Spark 與 Deltalake 的應用的時候,需要建立很多的 Table 與 Database 等資源,這些 Table 的資源究竟是怎麼管理的?就是 Hive Metastore 的角色,我們在很自然使用 Spark SQL 的時候,是否真正了解背後發生了什麼事情?本篇我們紀錄如何在 Databricks 上面使用客製化的 Hive Metastore。
詳細內容
最近在學習有關 Spark 跑在 GPU 上面的新技術 (Rapid) 本篇記錄一些有用的學習資源,最直接的就是看 Rapids 的 Github。但是直接看 Code 的缺點就是一下子太多資訊,所以如果能夠配合著一些概念性的影片介紹就能夠很快的了解 Rapids 的架構。
詳細內容檸檬爸在開發 Spark, Java, Scala 程式的時候很常遇到 NoSuchMethodError/ClassNotFound 這兩個錯誤,通常出現這兩個錯誤訊息的時候,主要原因是因為 Java Package 的 Dependency Conflict,在開發 Spark 的應用的時候究竟要怎麽去處理會比較好?本篇想要紀錄幾個常用的解法,包含Java 指令, JD-GUI 與 Maven Dependency:Tree 的介紹。
詳細內容前幾篇記錄了有關 K8S 與 Spark 的應用與一些 K8S 的常用指令,最近需要研究如何把 NFS 掛載上 K8S 裡面的 Pod,最主要的目的是要模擬出一個封閉的運算環境,在一個封閉的伺服器群集裡面,最好的分享檔案的方式就是利用像是 NAS 或是 NFS 等等的服務,本篇記錄一些在 Azure 環境裡面創造出 NFS 服務給 Kubernetes 使用遇到的一些挑戰與經驗。
詳細內容