[BigData] Apache Superset 安裝簡介
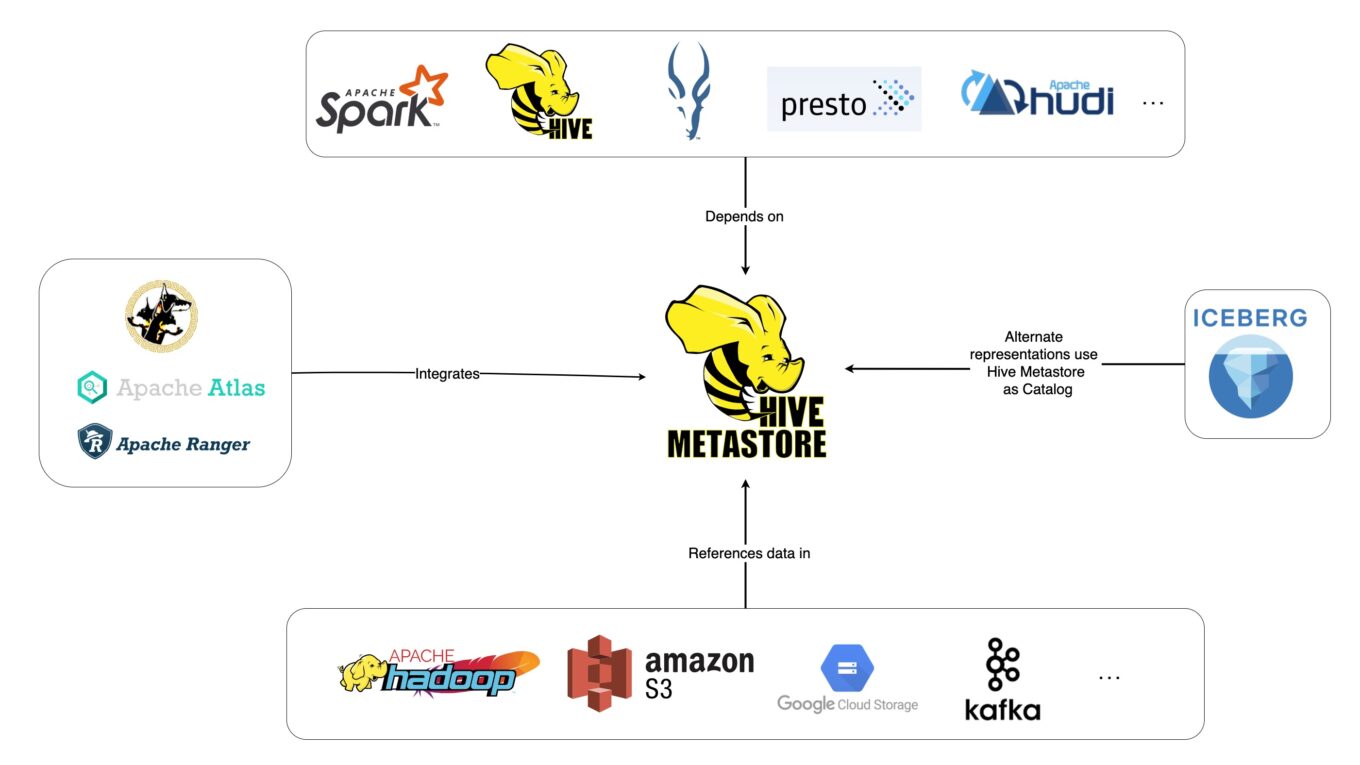
本篇想要記錄在實作安裝 Apache Superset 並且配合後端 HIVE 的資料庫進行資料呈現,一開始以為是要在 superset_config.py 內部設定SQLALCHEMY_DATABASE_URI 到指定的 Hive Server,後來了解到那是 Superset 內部 Database, Dataset 與 Charts 設定的儲存位置,本篇參考 Apache Superset 的網站實作安裝 Superset,希望對讀者有所幫助。
詳細內容