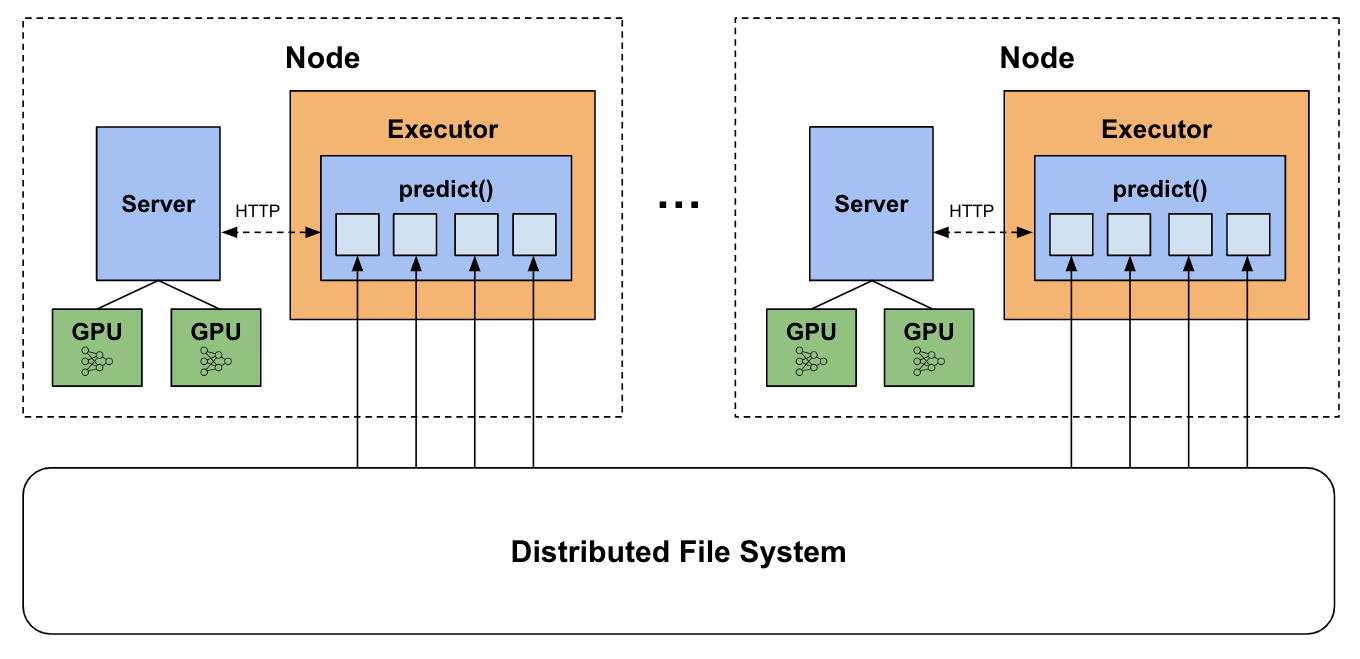
[LLM] Spark + Local vLLM Server
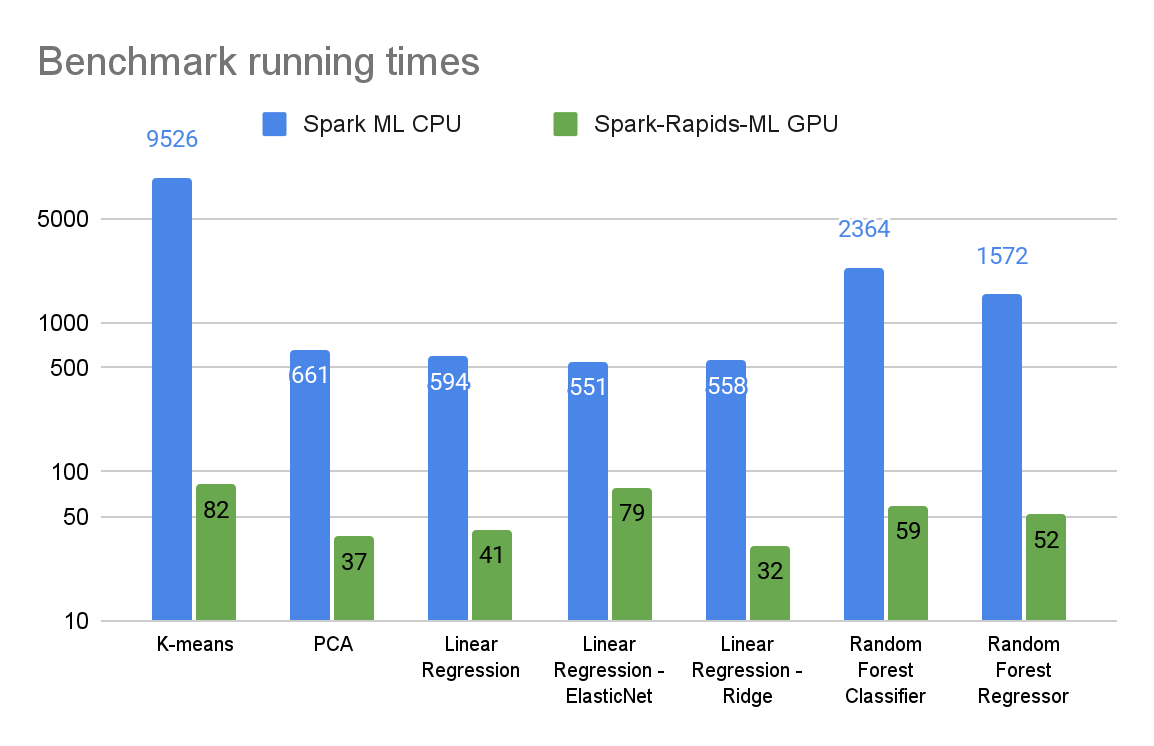
前陣子接收到 Nvidia 分享的這篇 Blog, Accelerate Deep Learning and LLM Inference with Apache Spark in the Cloud,開啟了檸檬爸在結合 Spark 與 Deep Learning/LLM 的想像,配合一些之前實作過 vLLM 的經驗,本篇紀錄利用 Spark + Local vLLM Server 達成加速批次推論的目的過程中遇到的種種坑。
詳細內容