
[ML] Fine Tune Spark NLP QA model
使用 Spark NLP 去執行 Question Answering 的範例,可以參考 JohnSnowLabs 裡面很多的 Question Answering 模型,例如 Roberta QA Model,至於要怎麼去 Fine Tune QA 模型?在 Spark NLP 裡面並沒有講解得很清楚,本篇想要記錄如何 Fine Tune 一個自己的 QA 模型供 Spark NLP 來使用?
精神:利用 HuggingFace transformer 套件做 Fine Tune 結束後供 SparkNLP 使用
關於 Fine Tune 一個 QA 的模型,在台大李宏毅教授開設的機器學習課程裡,HW7 利用 Pytorch 去 Fine Tune QA 模型 ,我們實作的經驗在一台安裝好 Nvidia Driver 跟 nvidia-util-515 的 VM 的 docker 裡面,Pytorch 的程式可以很輕易利用 GPU 做訓練,有關 QA model 的 Fine Tuning,Hugging Face 的網站上面有一些範例,主要分成利用 Trainer 或者是自己定義客製化的 Optimizer 來做訓練,以下我們整理了兩個利用 Pytorch 微調模型的方法。
Fine Tune in PyTorch using TrainingArguments :
首先先載入已經訓練好的 Tokenizer 與 Question Answering 模型:
from transformers import AutoTokenizer
model_checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)接著利用 transformers 內部提供的 TrainingArguments 設定訓練的參數
from transformers import TrainingArguments
args = TrainingArguments(
"bert-finetuned-squad",
evaluation_strategy="no",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
fp16=True,
push_to_hub=True,
)呼叫 Trainer 對 model 做訓練:
from transformers import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=validation_dataset,
tokenizer=tokenizer,
)
trainer.train()Customizing Fine Tune (李宏毅教授 HW7 的範例)
另外也可以自己客製化想要的微調方法,例如不同 Optimizer 的選擇,這個方法提供更多的彈性,但是也相對比較困難。
from accelerate import Accelerator
model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
!! hyperparameters
num_epoch = 1
validation = True
logging_step = 100
learning_rate = 1e-5
optimizer = AdamW(model.parameters(), lr=learning_rate)
train_batch_size = 8
!!!! TODO: gradient_accumulation (optional) !!!!
! Note: train_batch_size * gradient_accumulation_steps = effective batch size
! If CUDA out of memory, you can make train_batch_size lower and gradient_accumulation_steps upper
! Doc: https://huggingface.co/docs/accelerate/usage_guides/gradient_accumulation
gradient_accumulation_steps = 16
! dataloader
! Note: Do NOT change batch size of dev_loader / test_loader !
! Although batch size=1, it is actually a batch consisting of several windows from the same QA pair
train_loader = DataLoader(train_set, batch_size=train_batch_size, shuffle=True, pin_memory=True)
dev_loader = DataLoader(dev_set, batch_size=1, shuffle=False, pin_memory=True)
test_loader = DataLoader(test_set, batch_size=1, shuffle=False, pin_memory=True)
! Change "fp16_training" to True to support automatic mixed
! precision training (fp16)
fp16_training = True
if fp16_training:
accelerator = Accelerator(mixed_precision="fp16")
else:
accelerator = Accelerator()
! Documentation for the toolkit: https://huggingface.co/docs/accelerate/
model, optimizer, train_loader = accelerator.prepare(model, optimizer, train_loader)
model.train()
print("Start Training ...")
for epoch in range(num_epoch):
step = 1
train_loss = train_acc = 0
for data in tqdm(train_loader):
! Load all data into GPU
data = [i.to(device) for i in data]
! Model inputs: input_ids, token_type_ids, attention_mask, start_positions, end_positions (Note: only "input_ids" is mandatory)
! Model outputs: start_logits, end_logits, loss (return when start_positions/end_positions are provided)
output = model(input_ids=data[0], token_type_ids=data[1], attention_mask=data[2], start_positions=data[3], end_positions=data[4])
! Choose the most probable start position / end position
start_index = torch.argmax(output.start_logits, dim=1)
end_index = torch.argmax(output.end_logits, dim=1)
! Prediction is correct only if both start_index and end_index are correct
train_acc += ((start_index == data[3]) & (end_index == data[4])).float().mean()
train_loss += output.loss
accelerator.backward(output.loss)
step += 1
optimizer.step()
optimizer.zero_grad()
if step % logging_step == 0:
print(f"Epoch {epoch + 1}| Step {step}| loss = {train_loss.item() / logging_step:.3f}, acc = {train_acc / logging_step:.3f}")
train_loss = train_acc = 0備註:以上我們提供的是利用 HuggingFace 內的 Pytorch 來做訓練,如果之後要能夠給 SparkNLP 載入的話必須要用使用 HuggingFace 提供的 Tensorflow 範例。
連接 HuggingFace 與 Spark NLP
HuggingFace 也給出許多範例可以將 pytorch 訓練好的模型存在主機端,然後在利用 Spark NLP 裡面的 loadSavedModel 函式將模型載入,以下放上 BertEmbeddings 與 BertForQuestionAnswering 的範例轉換,更多範例可以參考連結。
比較訓練前與訓練後的 QA 模型效能
我們先利用 SparkNLP 演示訓練前後的 QA model 效能,我們使用 bert-base-cased 模型當作訓練前的模型,基本上這個模型並沒有經過 QA 的訓練所以效果很差,參考 HuggingFace 的程式碼:
步驟一:先載入 Tokenizer 與 QA 模型
from transformers import AutoTokenizer
from transformers import TFBertForQuestionAnswering
MODEL_NAME = 'bert-base-cased'
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
tokenizer.save_pretrained('/mnt/{}_tokenizer/'.format(MODEL_NAME))
model = TFBertForQuestionAnswering.from_pretrained(MODEL_NAME)步驟二:接著將 HuggingFace 上面的 model 輸出到 /mnt/bert-base-cased 的路徑下面
import tensorflow as tf
@tf.function(
input_signature=[
{
"input_ids": tf.TensorSpec((None, None), tf.int32, name="input_ids"),
"attention_mask": tf.TensorSpec((None, None), tf.int32, name="attention_mask"),
"token_type_ids": tf.TensorSpec((None, None), tf.int32, name="token_type_ids"),
}
]
)
def serving_fn(input):
return model(input)
model.save_pretrained("/mnt/{}".format(MODEL_NAME), saved_model=True, signatures={"serving_default": serving_fn})步驟三:然後利用 SparkNLP 的程式碼做 QA 回答,首先先初始化 SparkNLP
import sparknlp
spark = sparknlp.start()步驟四:儲存成 SparkNLP 可以看得懂的模型
from sparknlp.annotator import *
from sparknlp.base import *
spanClassifier = BertForQuestionAnswering.loadSavedModel(
'/mnt/{}/saved_model/1'.format(MODEL_NAME),
spark
)\
.setInputCols(["document_question",'document_context'])\
.setOutputCol("answer")\
.setCaseSensitive(False)\
.setMaxSentenceLength(512)
spanClassifier.write().overwrite().save("file:///mnt/{}_spark_nlp".format(MODEL_NAME))步驟五:接著執行預測
from sparknlp.annotator import *
from sparknlp.base import *
document_assembler = MultiDocumentAssembler() \
.setInputCols(["question", "context"]) \
.setOutputCols(["document_question", "document_context"])
spanClassifier_loaded = BertForQuestionAnswering.load("file:///mnt/{}_spark_nlp".format(MODEL_NAME))\
.setInputCols(["document_question", 'document_context'])\
.setOutputCol("answer")
pipeline = Pipeline().setStages([
document_assembler,
spanClassifier_loaded
])
example = spark.createDataFrame([["Where do I live?", "My name is Sarah and I live in London."]]).toDF("question", "context")
result = pipeline.fit(example).transform(example)
result.select("answer.result").show(1, False)但是效果不好,當問題是 My name is Sarah and I live in London. 問題是 Where do I live ? 的時候會找不到答案,如下圖所示。
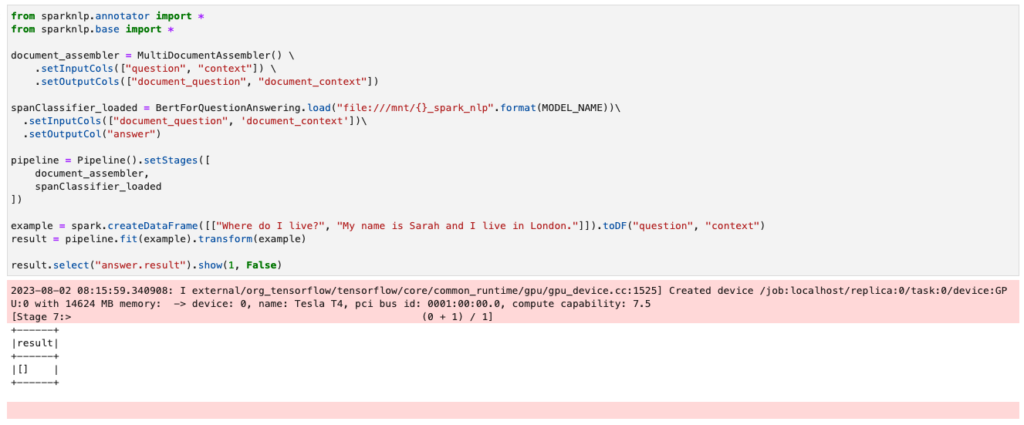
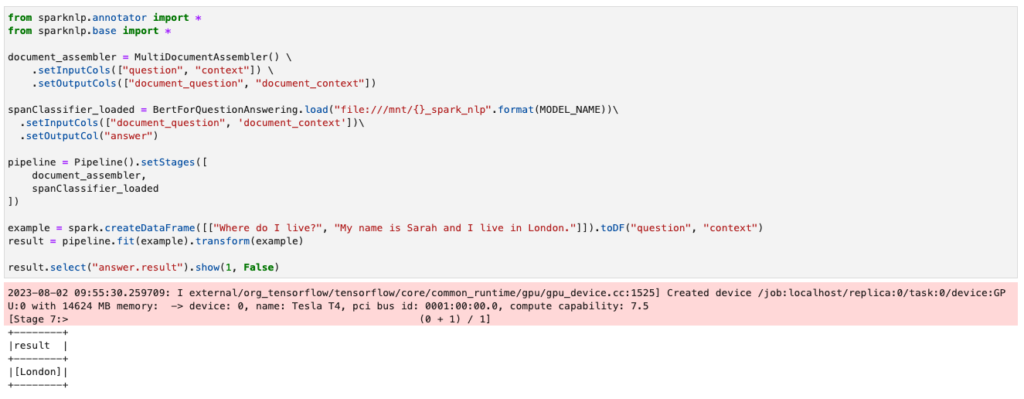
利用 Squad 資料集訓練 model
Fine Tune 與否的差別就是在上述步驟一將 model 載入之後,於步驟二執行之前利用 Squad 資料及進行訓練,此處的程式碼是參考 HuggingFace 針對 QA model 訓練的教學,首先先載入 Squad 資料集。
from datasets import load_dataset
raw_datasets = load_dataset("squad")接著定義前處理函數
max_length = 384
stride = 128
def preprocess_training_examples(examples):
questions = [q.strip() for q in examples["question"]]
inputs = tokenizer(
questions,
examples["context"],
max_length=max_length,
truncation="only_second",
stride=stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
offset_mapping = inputs.pop("offset_mapping")
sample_map = inputs.pop("overflow_to_sample_mapping")
answers = examples["answers"]
start_positions = []
end_positions = []
for i, offset in enumerate(offset_mapping):
sample_idx = sample_map[i]
answer = answers[sample_idx]
start_char = answer["answer_start"][0]
end_char = answer["answer_start"][0] + len(answer["text"][0])
sequence_ids = inputs.sequence_ids(i)
idx = 0
while sequence_ids[idx] != 1:
idx += 1
context_start = idx
while sequence_ids[idx] == 1:
idx += 1
context_end = idx - 1
if offset[context_start][0] > start_char or offset[context_end][1] < end_char:
start_positions.append(0)
end_positions.append(0)
else:
idx = context_start
while idx <= context_end and offset[idx][0] <= start_char:
idx += 1
start_positions.append(idx - 1)
idx = context_end
while idx >= context_start and offset[idx][1] >= end_char:
idx -= 1
end_positions.append(idx + 1)
inputs["start_positions"] = start_positions
inputs["end_positions"] = end_positions
return inputs前處理 Training 與 Validation 的資料,以下結果可以看出 Squad 的訓練問答集總共有 87599 個,驗證資料集總共有 10570 個。
train_dataset = raw_datasets["train"].map(
preprocess_training_examples,
batched=True,
remove_columns=raw_datasets["train"].column_names,
)
len(raw_datasets["train"]), len(train_dataset)
(87599, 88729)
validation_dataset = raw_datasets["validation"].map(
preprocess_training_examples,
batched=True,
remove_columns=raw_datasets["validation"].column_names,
)
len(raw_datasets["validation"]), len(validation_dataset)
(10570, 10822)將資料集轉換成 TensorFlow 的格式,這邊我們只選擇了 2000 筆資料做訓練就能夠達到不錯的效果。
tf_train_set = train_dataset.select(range(2000)).to_tf_dataset(
columns=["attention_mask", "input_ids", "start_positions", "end_positions"],
shuffle=True,
batch_size=16,
collate_fn=data_collator,
)
tf_validation_set = validation_dataset.select(range(2000)).to_tf_dataset(
columns=["attention_mask", "input_ids", "start_positions", "end_positions"],
shuffle=False,
batch_size=16,
collate_fn=data_collator,
)創建 optimizer 並且設定訓練參數
from transformers import create_optimizer
batch_size = 16
num_epochs = 2
total_train_steps = (len(train_dataset) // batch_size) * num_epochs
optimizer, schedule = create_optimizer(
init_lr=2e-5,
num_warmup_steps=0,
num_train_steps=total_train_steps,
)
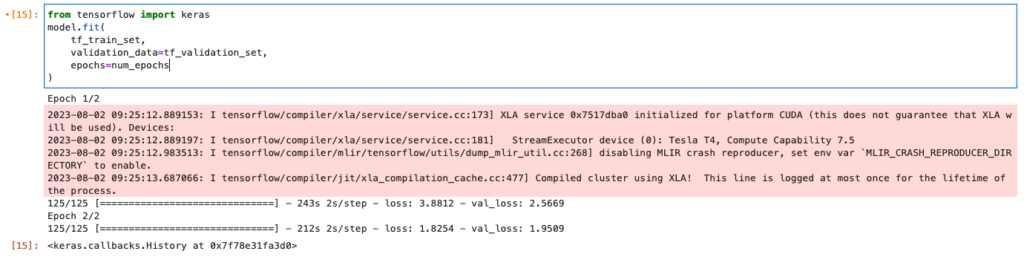
model.compile(optimizer=optimizer)開始訓練
from tensorflow import keras
model.fit(
tf_train_set,
validation_data=tf_validation_set,
epochs=num_epochs
)此處我們利用 Azure 上的 VM 配合 Nvidia T4 GPU
接續利用步驟二三四五就可以把訓練好的模型導出給 SparkNLP 使用