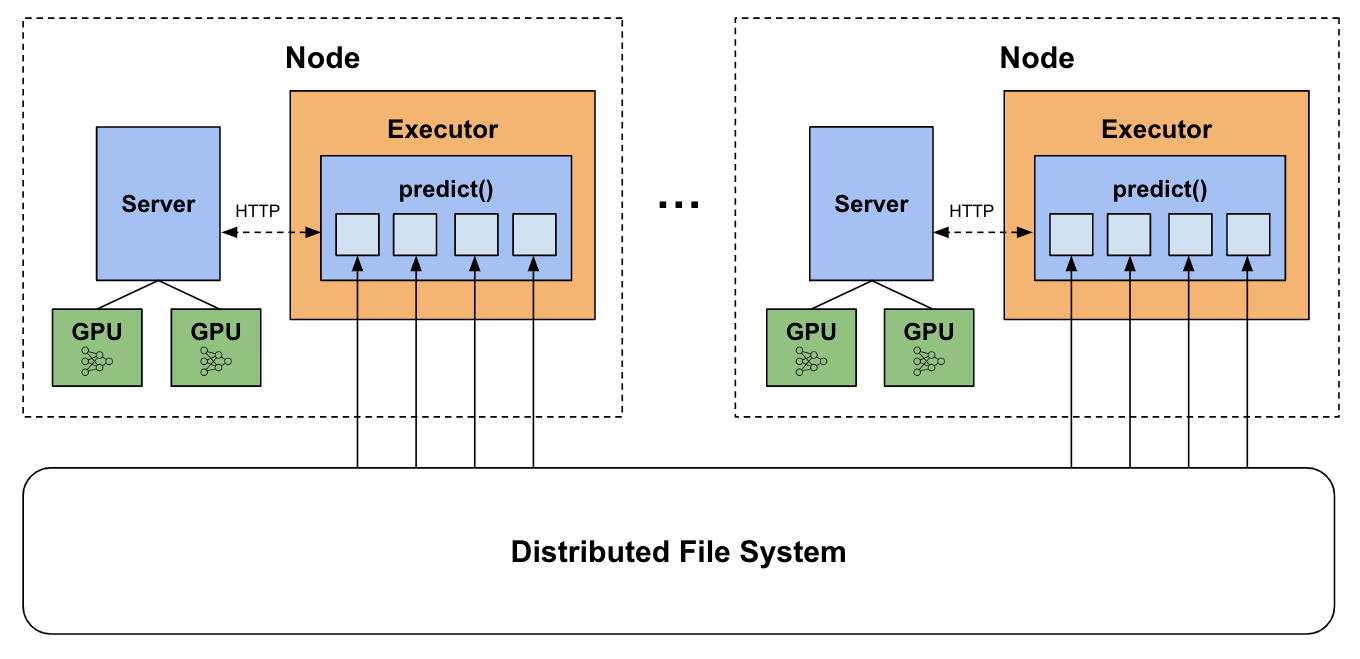
[LLM] Spark + Local vLLM Server
前陣子接收到 Nvidia 分享的這篇 Blog, Accelerate Deep Learning and LLM Inference with Apache Spark in the Cloud,開啟了檸檬爸在結合 Spark 與 Deep Learning/LLM 的想像,配合一些之前實作過 vLLM 的經驗,本篇紀錄利用 Spark + Local vLLM Server 達成加速批次推論的目的過程中遇到的種種坑。
需要先安裝 vLLM Server 在雲端的Docker 映像檔中,安裝 vllm 可以參考連結,基本上就是執行以下的指令:
git clone https://github.com/vllm-project/vllm.git
cd vllm
VLLM_USE_PRECOMPILED=1 pip3 install --editable .Note: 特別需要注意 pyspark 在整個 Spark 的 python 版本必須要跟 vLLM 一致,因此建議不要使用 uv 安裝。
執行 Spark Rapids PySpark 腳本
可以參考執行 Spark Rapids 提供的腳本將 vLLM 跑在 Spark 叢集的每一台機器上。
以下的錯誤訊息會發生,主要是因為如果使用 spark.dynamicAllocation 一開始沒有 executor,會導致 num_executor 為零,因此需要以下兩個 Spark Conf 設定:
spark.dynamicAllocation.enabled false
spark.executor.instances 1設定至少一個 executor,這邊不能夠使用 dynamicAllocation。
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
Cell In[7], line 1
----> 1 server_manager.start_servers(tensor_parallel_size=tensor_parallel_size,
2 gpu_memory_utilization=0.95,
3 max_model_len=6600,
4 #task="generate",
5 wait_retries=100)
File /mnt/spark-a9c7f16d-f4e5-47d3-8c97-7221d7a3bc2d/userFiles-96583b4a-6922-45ae-a333-0f3a55dc9b8f/server_utils.py:566, in VLLMServerManager.start_servers(self, wait_retries, wait_timeout, **kwargs)
551 """
552 Start vLLM OpenAI-compatible servers across the cluster.
553
(...)
562 Dictionary of hostname -> (server PID, [port])
563 """
564 self._validate_vllm_kwargs(kwargs)
--> 566 return super().start_servers(
567 start_server_fn=_start_vllm_server_task,
568 wait_retries=wait_retries,
569 wait_timeout=wait_timeout,
570 **kwargs,
571 )
File /mnt/spark-a9c7f16d-f4e5-47d3-8c97-7221d7a3bc2d/userFiles-96583b4a-6922-45ae-a333-0f3a55dc9b8f/server_utils.py:373, in ServerManager.start_servers(self, start_server_fn, wait_retries, wait_timeout, **kwargs)
354 def start_servers(
355 self,
356 start_server_fn: Callable,
(...)
359 **kwargs,
360 ) -> Dict[str, Tuple[int, List[int]]]:
361 """
362 Start servers across the cluster.
363
(...)
371 Dictionary of hostname -> (server PID, [ports])
372 """
--> 373 node_rdd = self._get_node_rdd()
374 model_name = self.model_name
375 model_path = self.model_path
File /mnt/spark-a9c7f16d-f4e5-47d3-8c97-7221d7a3bc2d/userFiles-96583b4a-6922-45ae-a333-0f3a55dc9b8f/server_utils.py:313, in ServerManager._get_node_rdd(self)
311 """Create and configure RDD with stage-level scheduling for 1 task per executor."""
312 sc = self.spark.sparkContext
--> 313 node_rdd = sc.parallelize(list(range(self.num_executors)), self.num_executors)
314 return self._use_stage_level_scheduling(node_rdd)
File /usr/local/lib/python3.10/dist-packages/pyspark/context.py:812, in SparkContext.parallelize(self, c, numSlices)
809 if "__len__" not in dir(c):
810 c = list(c) # Make it a list so we can compute its length
811 batchSize = max(
--> 812 1, min(len(c) // numSlices, self._batchSize or 1024) # type: ignore[arg-type]
813 )
814 serializer = BatchedSerializer(self._unbatched_serializer, batchSize)
816 def reader_func(temp_filename: str) -> JavaObject:
ZeroDivisionError: integer division or modulo by zero另外參考 Notebook 範例 需要另外設定兩個 Spark Configuration
spark.sql.execution.arrow.pyspark.enabled true
spark.python.worker.reuse true接下來又發生其他的執行錯誤如以下所示,看起來主要是因為 vLLM 啟動失敗,這時候要去查看 executor logs 才會知道詳細的問題是什麼?
2025-12-14 16:19:03,639 - INFO - Requesting stage-level resources: (cores=24, gpu=1.0)
2025-12-14 16:19:03,641 - INFO - Starting 1 VLLM servers.
16:19:28.949 WARN TaskSetManager - Lost task 0.0 in stage 2.0 (TID 2) (10.0.0.100 executor 0): org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/home/spark-current/python/lib/pyspark.zip/pyspark/worker.py", line 1247, in main
process()
File "/home/spark-current/python/lib/pyspark.zip/pyspark/worker.py", line 1237, in process
out_iter = func(split_index, iterator)
File "/usr/local/lib/python3.10/dist-packages/pyspark/rdd.py", line 5342, in func
return f(iterator)
File "/mnt/spark-a3a762f1-3585-4202-b24f-68af898fe4d2/userFiles-4048e0dd-5462-4ead-a31e-4fe2484d3178/server_utils.py", line 393, in <lambda>
.mapPartitions(lambda _: start_server_fn(**start_args))
File "/mnt/spark-current/work/app-20251214161818-0015/0/server_utils.py", line 220, in _start_vllm_server_task
raise TimeoutError(
TimeoutError: Failure: vLLM server startup failed or timed out. Check the executor logs for more info.
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.handlePythonException(PythonRunner.scala:572)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:784)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:766)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:525)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at org.apache.spark.InterruptibleIterator.foreach(InterruptibleIterator.scala:28)
at scala.collection.generic.Growable.$plus$plus$eq(Growable.scala:62)
at scala.collection.generic.Growable.$plus$plus$eq$(Growable.scala:53)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:105)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:49)
at scala.collection.TraversableOnce.to(TraversableOnce.scala:366)
at scala.collection.TraversableOnce.to$(TraversableOnce.scala:364)
at org.apache.spark.InterruptibleIterator.to(InterruptibleIterator.scala:28)
at scala.collection.TraversableOnce.toBuffer(TraversableOnce.scala:358)
at scala.collection.TraversableOnce.toBuffer$(TraversableOnce.scala:358)
at org.apache.spark.InterruptibleIterator.toBuffer(InterruptibleIterator.scala:28)
at scala.collection.TraversableOnce.toArray(TraversableOnce.scala:345)
at scala.collection.TraversableOnce.toArray$(TraversableOnce.scala:339)
at org.apache.spark.InterruptibleIterator.toArray(InterruptibleIterator.scala:28)
at org.apache.spark.rdd.RDD.$anonfun$collect$2(RDD.scala:1049)
at org.apache.spark.SparkContext.$anonfun$runJob$5(SparkContext.scala:2433)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:93)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:166)
at org.apache.spark.scheduler.Task.run(Task.scala:141)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:620)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally(SparkErrorUtils.scala:64)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally$(SparkErrorUtils.scala:61)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:94)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:623)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635)
at java.base/java.lang.Thread.run(Thread.java:840)從 executor log 發現失敗的原因是因為 Memory 不足,調整 Memory 比例之後成功將 vLLM 開啟之後,在 stderr 裡面呈現的 log,可以看到 Qwen 模型有成功被跑起來。
21:11:48.122 INFO SpillFramework - Initialized SpillFramework. Host spill store max size is: 3221225472 B.
21:11:48.127 INFO AwsStorageExecutorPlugin - Initializing S3 Plugin on the Executor 0
21:11:48.139 INFO ExecutorPluginContainer - Initialized executor component for plugin com.nvidia.spark.SQLPlugin.
21:11:48.170 INFO CoarseGrainedExecutorBackend - Got assigned task 0
21:11:48.177 INFO Executor - Running task 0.0 in stage 0.0 (TID 0)
21:11:48.190 INFO Executor - Fetching spark://df47c4ef02f441a691ec50ef8a32a916000000.internal.cloudapp.net:35733/files/server_utils.py with timestamp 1765746697379
21:11:48.198 INFO Utils - Fetching spark://df47c4ef02f441a691ec50ef8a32a916000000.internal.cloudapp.net:35733/files/server_utils.py to /mnt/spark-bb1e5efc-b0a5-48f2-b12f-74c52c675d98/executor-889e4410-90bd-4ccb-91e4-0369221f9874/spark-43ccec49-e90b-4b65-98f6-2d4e1366de24/fetchFileTemp1858766223110752632.tmp
21:11:48.200 INFO Utils - Copying /mnt/spark-bb1e5efc-b0a5-48f2-b12f-74c52c675d98/executor-889e4410-90bd-4ccb-91e4-0369221f9874/spark-43ccec49-e90b-4b65-98f6-2d4e1366de24/21140649291765746697379_cache to /mnt/spark-current/work/app-20251214211135-0004/0/./server_utils.py
21:11:48.411 INFO SparkResourceAdaptor - startDedicatedTaskThread: threadId: 125108656997952, task id: 0
21:11:48.419 INFO TorrentBroadcast - Started reading broadcast variable 0 with 1 pieces (estimated total size 4.0 MiB)
21:11:48.446 INFO TransportClientFactory - Successfully created connection to df47c4ef02f441a691ec50ef8a32a916000000.internal.cloudapp.net/10.0.0.100:37915 after 1 ms (0 ms spent in bootstraps)
21:11:48.475 INFO MemoryStore - Block broadcast_0_piece0 stored as bytes in memory (estimated size 3.9 KiB, free 119.8 GiB)
21:11:48.482 INFO TorrentBroadcast - Reading broadcast variable 0 took 62 ms
21:11:48.508 INFO MemoryStore - Block broadcast_0 stored as values in memory (estimated size 6.1 KiB, free 119.8 GiB)
21:11:54.544 INFO PythonRunner - Times: total = 5960, boot = 416, init = 150, finish = 5394
21:11:54.554 INFO Executor - Finished task 0.0 in stage 0.0 (TID 0). 5605 bytes result sent to driver
21:11:54.669 INFO CoarseGrainedExecutorBackend - Got assigned task 1
21:11:54.669 INFO Executor - Running task 0.0 in stage 1.0 (TID 1)
21:11:54.675 INFO SparkResourceAdaptor - startDedicatedTaskThread: threadId: 125108656997952, task id: 1
21:11:54.676 INFO TorrentBroadcast - Started reading broadcast variable 1 with 1 pieces (estimated total size 4.0 MiB)
21:11:54.680 INFO MemoryStore - Block broadcast_1_piece0 stored as bytes in memory (estimated size 4.1 KiB, free 119.8 GiB)
21:11:54.682 INFO TorrentBroadcast - Reading broadcast variable 1 took 6 ms
21:11:54.683 INFO MemoryStore - Block broadcast_1 stored as values in memory (estimated size 6.3 KiB, free 119.8 GiB)
2025-12-14 21:11:54,885 - INFO - Starting vLLM server with command: /usr/bin/python3.10 -m vllm.entrypoints.openai.api_server --model /mnt/models --served-model-name qwen-2.5-14b --port 7000 --tensor_parallel_size 1 --gpu_memory_utilization 0.5 --max_model_len 6600
(APIServer pid=12109) INFO 12-14 21:12:00 [api_server.py:1351] vLLM API server version 0.13.0rc2.dev139+g9ccbf6b69
(APIServer pid=12109) INFO 12-14 21:12:00 [utils.py:253] non-default args: {'port': 7000, 'model': '/mnt/models', 'max_model_len': 6600, 'served_model_name': ['qwen-2.5-14b'], 'gpu_memory_utilization': 0.5}
(APIServer pid=12109) INFO 12-14 21:12:00 [model.py:514] Resolved architecture: Qwen2ForCausalLM
(APIServer pid=12109) INFO 12-14 21:12:00 [model.py:1652] Using max model len 6600
(APIServer pid=12109) INFO 12-14 21:12:01 [scheduler.py:228] Chunked prefill is enabled with max_num_batched_tokens=2048.
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:07 [core.py:93] Initializing a V1 LLM engine (v0.13.0rc2.dev139+g9ccbf6b69) with config: model='/mnt/models', speculative_config=None, tokenizer='/mnt/models', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=6600, download_dir=None, load_format=auto, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_fallback=False, disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01, cudagraph_metrics=False, enable_layerwise_nvtx_tracing=False), seed=0, served_model_name=qwen-2.5-14b, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'level': None, 'mode': <CompilationMode.VLLM_COMPILE: 3>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['none'], 'splitting_ops': ['vllm::unified_attention', 'vllm::unified_attention_with_output', 'vllm::unified_mla_attention', 'vllm::unified_mla_attention_with_output', 'vllm::mamba_mixer2', 'vllm::mamba_mixer', 'vllm::short_conv', 'vllm::linear_attention', 'vllm::plamo2_mamba_mixer', 'vllm::gdn_attention_core', 'vllm::kda_attention', 'vllm::sparse_attn_indexer'], 'compile_mm_encoder': False, 'compile_sizes': [], 'compile_ranges_split_points': [2048], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.FULL_AND_PIECEWISE: (2, 1)>, 'cudagraph_num_of_warmups': 1, 'cudagraph_capture_sizes': [1, 2, 4, 8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96, 104, 112, 120, 128, 136, 144, 152, 160, 168, 176, 184, 192, 200, 208, 216, 224, 232, 240, 248, 256, 272, 288, 304, 320, 336, 352, 368, 384, 400, 416, 432, 448, 464, 480, 496, 512], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': False, 'fuse_act_quant': False, 'fuse_attn_quant': False, 'eliminate_noops': True, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 512, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>, 'evaluate_guards': False}, 'local_cache_dir': None}
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:08 [parallel_state.py:1203] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://10.0.0.100:37021 backend=nccl
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:08 [parallel_state.py:1411] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank 0
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:09 [gpu_model_runner.py:3562] Starting to load model /mnt/models...
(EngineCore_DP0 pid=12131) /usr/local/lib/python3.10/dist-packages/tvm_ffi/_optional_torch_c_dlpack.py:174: UserWarning: Failed to JIT torch c dlpack extension, EnvTensorAllocator will not be enabled.
(EngineCore_DP0 pid=12131) We recommend installing via `pip install torch-c-dlpack-ext`
(EngineCore_DP0 pid=12131) warnings.warn(
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:10 [cuda.py:412] Using FLASH_ATTN attention backend out of potential backends: ('FLASH_ATTN', 'FLASHINFER', 'TRITON_ATTN', 'FLEX_ATTENTION')
Loading safetensors checkpoint shards: 0% Completed | 0/8 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 12% Completed | 1/8 [00:00<00:02, 2.49it/s]
Loading safetensors checkpoint shards: 25% Completed | 2/8 [00:00<00:02, 2.16it/s]
Loading safetensors checkpoint shards: 38% Completed | 3/8 [00:01<00:02, 2.07it/s]
Loading safetensors checkpoint shards: 50% Completed | 4/8 [00:01<00:01, 2.03it/s]
Loading safetensors checkpoint shards: 62% Completed | 5/8 [00:02<00:01, 2.02it/s]
Loading safetensors checkpoint shards: 75% Completed | 6/8 [00:02<00:00, 2.01it/s]
Loading safetensors checkpoint shards: 88% Completed | 7/8 [00:03<00:00, 2.00it/s]
Loading safetensors checkpoint shards: 100% Completed | 8/8 [00:03<00:00, 2.34it/s]
Loading safetensors checkpoint shards: 100% Completed | 8/8 [00:03<00:00, 2.16it/s]
(EngineCore_DP0 pid=12131)
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:14 [default_loader.py:308] Loading weights took 3.75 seconds
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:15 [gpu_model_runner.py:3659] Model loading took 27.5681 GiB memory and 5.643590 seconds
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:22 [backends.py:643] Using cache directory: /root/.cache/vllm/torch_compile_cache/32b5011098/rank_0_0/backbone for vLLM's torch.compile
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:22 [backends.py:703] Dynamo bytecode transform time: 7.37 s
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:29 [backends.py:261] Cache the graph of compile range (1, 2048) for later use
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:40 [backends.py:278] Compiling a graph for compile range (1, 2048) takes 13.15 s
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:40 [monitor.py:34] torch.compile takes 20.51 s in total
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:41 [gpu_worker.py:375] Available KV cache memory: 10.48 GiB
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:41 [kv_cache_utils.py:1291] GPU KV cache size: 57,216 tokens
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:41 [kv_cache_utils.py:1296] Maximum concurrency for 6,600 tokens per request: 8.66x
Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 100%|██████████| 51/51 [00:03<00:00, 14.71it/s]
Capturing CUDA graphs (decode, FULL): 100%|██████████| 35/35 [00:01<00:00, 18.59it/s]
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:47 [gpu_model_runner.py:4610] Graph capturing finished in 6 secs, took 3.05 GiB
(EngineCore_DP0 pid=12131) INFO 12-14 21:12:47 [core.py:259] init engine (profile, create kv cache, warmup model) took 32.31 seconds
(APIServer pid=12109) INFO 12-14 21:12:48 [api_server.py:1099] Supported tasks: ['generate']
(APIServer pid=12109) WARNING 12-14 21:12:48 [model.py:1478] Default sampling parameters have been overridden by the model's Hugging Face generation config recommended from the model creator. If this is not intended, please relaunch vLLM instance with `--generation-config vllm`.
(APIServer pid=12109) INFO 12-14 21:12:48 [serving_responses.py:201] Using default chat sampling params from model: {'repetition_penalty': 1.05, 'temperature': 0.7, 'top_k': 20, 'top_p': 0.8}
(APIServer pid=12109) INFO 12-14 21:12:48 [serving_chat.py:137] Using default chat sampling params from model: {'repetition_penalty': 1.05, 'temperature': 0.7, 'top_k': 20, 'top_p': 0.8}
(APIServer pid=12109) INFO 12-14 21:12:48 [serving_completion.py:77] Using default completion sampling params from model: {'repetition_penalty': 1.05, 'temperature': 0.7, 'top_k': 20, 'top_p': 0.8}
(APIServer pid=12109) INFO 12-14 21:12:48 [serving_chat.py:137] Using default chat sampling params from model: {'repetition_penalty': 1.05, 'temperature': 0.7, 'top_k': 20, 'top_p': 0.8}
(APIServer pid=12109) INFO 12-14 21:12:48 [api_server.py:1425] Starting vLLM API server 0 on http://0.0.0.0:7000
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:38] Available routes are:
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /openapi.json, Methods: GET, HEAD
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /docs, Methods: GET, HEAD
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /docs/oauth2-redirect, Methods: GET, HEAD
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /redoc, Methods: GET, HEAD
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /scale_elastic_ep, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /is_scaling_elastic_ep, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /tokenize, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /detokenize, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /inference/v1/generate, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /pause, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /resume, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /is_paused, Methods: GET
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /metrics, Methods: GET
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /health, Methods: GET
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /load, Methods: GET
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /v1/models, Methods: GET
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /version, Methods: GET
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /v1/responses, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /v1/responses/{response_id}, Methods: GET
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /v1/responses/{response_id}/cancel, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /v1/messages, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /v1/chat/completions, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /v1/completions, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /v1/audio/transcriptions, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /v1/audio/translations, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /ping, Methods: GET
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /ping, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /invocations, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /classify, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /v1/embeddings, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /score, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /v1/score, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /rerank, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /v1/rerank, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /v2/rerank, Methods: POST
(APIServer pid=12109) INFO 12-14 21:12:48 [launcher.py:46] Route: /pooling, Methods: POST
(APIServer pid=12109) INFO: Started server process [12109]
(APIServer pid=12109) INFO: Waiting for application startup.
(APIServer pid=12109) INFO: Application startup complete.
(APIServer pid=12109) INFO: 127.0.0.1:47994 - "GET /health HTTP/1.1" 200 OK
21:12:49.954 INFO BarrierTaskContext - Task 1 from Stage 1(Attempt 0) has entered the global sync, current barrier epoch is 0.
21:12:50.958 INFO BarrierTaskContext - Task 1 from Stage 1(Attempt 0) finished global sync successfully, waited for 1 seconds, current barrier epoch is 1.
21:12:50.958 INFO PythonRunner - Times: total = 56273, boot = 3, init = 146, finish = 56124
21:12:50.961 INFO Executor - Finished task 0.0 in stage 1.0 (TID 1). 1330 bytes result sent to driver
21:13:07.898 INFO CoarseGrainedExecutorBackend - Got assigned task 2
21:13:07.899 INFO Executor - Running task 0.0 in stage 2.0 (TID 2)
21:13:07.901 INFO SparkResourceAdaptor - startDedicatedTaskThread: threadId: 125108656997952, task id: 2
21:13:07.902 INFO TorrentBroadcast - Started reading broadcast variable 2 with 1 pieces (estimated total size 4.0 MiB)
21:13:07.906 INFO MemoryStore - Block broadcast_2_piece0 stored as bytes in memory (estimated size 3.9 KiB, free 119.8 GiB)
21:13:07.908 INFO TorrentBroadcast - Reading broadcast variable 2 took 6 ms
21:13:07.909 INFO MemoryStore - Block broadcast_2 stored as values in memory (estimated size 6.1 KiB, free 119.8 GiB)
21:13:13.435 INFO PythonRunner - Times: total = 5523, boot = 3, init = 140, finish = 5380
21:13:13.436 INFO Executor - Finished task 0.0 in stage 2.0 (TID 2). 5519 bytes result sent to driver
21:13:13.508 INFO CoarseGrainedExecutorBackend - Got assigned task 3
21:13:13.509 INFO Executor - Running task 0.0 in stage 3.0 (TID 3)
21:13:13.512 INFO SparkResourceAdaptor - startDedicatedTaskThread: threadId: 125108656997952, task id: 3
21:13:13.513 INFO TorrentBroadcast - Started reading broadcast variable 3 with 1 pieces (estimated total size 4.0 MiB)
21:13:13.517 INFO MemoryStore - Block broadcast_3_piece0 stored as bytes in memory (estimated size 4.1 KiB, free 119.8 GiB)
21:13:13.519 INFO TorrentBroadcast - Reading broadcast variable 3 took 5 ms
21:13:13.520 INFO MemoryStore - Block broadcast_3 stored as values in memory (estimated size 6.3 KiB, free 119.8 GiB)
2025-12-14 21:13:13,717 - INFO - Starting vLLM server with command: /usr/bin/python3.10 -m vllm.entrypoints.openai.api_server --model /azure/models --served-model-name qwen-2.5-14b --port 7001 --tensor_parallel_size 1 --gpu_memory_utilization 0.5 --max_model_len 6600
(APIServer pid=12548) INFO 12-14 21:13:19 [api_server.py:1351] vLLM API server version 0.13.0rc2.dev139+g9ccbf6b69
(APIServer pid=12548) INFO 12-14 21:13:19 [utils.py:253] non-default args: {'port': 7001, 'model': '/azure/models', 'max_model_len': 6600, 'served_model_name': ['qwen-2.5-14b'], 'gpu_memory_utilization': 0.5}嘗試改成 openai/gpt-oss-20b 的模型之後,產生了另外的問題,發現問題主要是因為 vllm 在安裝的時候我們使用的是 Build wheel from source 的方法,所以出現了 C++ 程式不匹配的問題,我們後來利用 Pre-built wheels 的方式安裝 vllm 就沒有再出現一樣的問題了,GPT-OSS-20B 有用到 Multiple-of-Expert (MoE) 的技術,所以部署上相對 Qwen 較困難一點。
12:40:32.462 INFO MemoryStore - Block broadcast_2 stored as values in memory (estimated size 6.3 KiB, free 119.8 GiB)
2025-12-16 12:40:32,655 - INFO - Starting vLLM server with command: /usr/bin/python3.10 -m vllm.entrypoints.openai.api_server --model /mnt/gpt-oss-20b --served-model-name openai/gpt-oss-20b --port 7000 --tensor_parallel_size 1 --gpu_memory_utilization 0.65 --max_model_len 6600 --task generate
WARNING 12-16 12:40:38 [argparse_utils.py:82] argument 'task' is deprecated
(APIServer pid=14588) INFO 12-16 12:40:38 [api_server.py:1772] vLLM API server version 0.12.0
(APIServer pid=14588) INFO 12-16 12:40:38 [utils.py:253] non-default args: {'port': 7000, 'model': '/mnt/gpt-oss-20b', 'task': 'generate', 'max_model_len': 6600, 'served_model_name': ['openai/gpt-oss-20b'], 'gpu_memory_utilization': 0.65}
(APIServer pid=14588) INFO 12-16 12:40:38 [model.py:637] Resolved architecture: GptOssForCausalLM
(APIServer pid=14588) ERROR 12-16 12:40:38 [repo_utils.py:65] Error retrieving safetensors: Repo id must be in the form 'repo_name' or 'namespace/repo_name': '/mnt/gpt-oss-20b'. Use `repo_type` argument if needed., retrying 1 of 2
(APIServer pid=14588) ERROR 12-16 12:40:40 [repo_utils.py:63] Error retrieving safetensors: Repo id must be in the form 'repo_name' or 'namespace/repo_name': '/mnt/gpt-oss-20b'. Use `repo_type` argument if needed.
(APIServer pid=14588) INFO 12-16 12:40:40 [model.py:2086] Downcasting torch.float32 to torch.bfloat16.
(APIServer pid=14588) INFO 12-16 12:40:40 [model.py:1750] Using max model len 6600
(APIServer pid=14588) INFO 12-16 12:40:41 [scheduler.py:228] Chunked prefill is enabled with max_num_batched_tokens=2048.
(APIServer pid=14588) INFO 12-16 12:40:41 [config.py:274] Overriding max cuda graph capture size to 1024 for performance.
(EngineCore_DP0 pid=14609) INFO 12-16 12:40:48 [core.py:93] Initializing a V1 LLM engine (v0.12.0) with config: model='/mnt/gpt-oss-20b', speculative_config=None, tokenizer='/mnt/gpt-oss-20b', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=6600, download_dir=None, load_format=auto, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, disable_custom_all_reduce=False, quantization=mxfp4, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_fallback=False, disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='openai_gptoss', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01), seed=0, served_model_name=openai/gpt-oss-20b, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'level': None, 'mode': <CompilationMode.VLLM_COMPILE: 3>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['none'], 'splitting_ops': ['vllm::unified_attention', 'vllm::unified_attention_with_output', 'vllm::unified_mla_attention', 'vllm::unified_mla_attention_with_output', 'vllm::mamba_mixer2', 'vllm::mamba_mixer', 'vllm::short_conv', 'vllm::linear_attention', 'vllm::plamo2_mamba_mixer', 'vllm::gdn_attention_core', 'vllm::kda_attention', 'vllm::sparse_attn_indexer'], 'compile_mm_encoder': False, 'compile_sizes': [], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.FULL_AND_PIECEWISE: (2, 1)>, 'cudagraph_num_of_warmups': 1, 'cudagraph_capture_sizes': [1, 2, 4, 8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96, 104, 112, 120, 128, 136, 144, 152, 160, 168, 176, 184, 192, 200, 208, 216, 224, 232, 240, 248, 256, 272, 288, 304, 320, 336, 352, 368, 384, 400, 416, 432, 448, 464, 480, 496, 512, 528, 544, 560, 576, 592, 608, 624, 640, 656, 672, 688, 704, 720, 736, 752, 768, 784, 800, 816, 832, 848, 864, 880, 896, 912, 928, 944, 960, 976, 992, 1008, 1024], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': False, 'fuse_act_quant': False, 'fuse_attn_quant': False, 'eliminate_noops': True, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 1024, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>}, 'local_cache_dir': None}
(EngineCore_DP0 pid=14609) INFO 12-16 12:40:48 [parallel_state.py:1200] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://10.0.0.100:55309 backend=nccl
(EngineCore_DP0 pid=14609) INFO 12-16 12:40:48 [parallel_state.py:1408] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank 0
(EngineCore_DP0 pid=14609) INFO 12-16 12:40:49 [gpu_model_runner.py:3467] Starting to load model /mnt/gpt-oss-20b...
(EngineCore_DP0 pid=14609) /usr/local/lib/python3.10/dist-packages/tvm_ffi/_optional_torch_c_dlpack.py:174: UserWarning: Failed to JIT torch c dlpack extension, EnvTensorAllocator will not be enabled.
(EngineCore_DP0 pid=14609) We recommend installing via `pip install torch-c-dlpack-ext`
(EngineCore_DP0 pid=14609) warnings.warn(
(EngineCore_DP0 pid=14609) INFO 12-16 12:40:51 [cuda.py:411] Using TRITON_ATTN attention backend out of potential backends: ['TRITON_ATTN']
(EngineCore_DP0 pid=14609) INFO 12-16 12:40:51 [layer.py:379] Enabled separate cuda stream for MoE shared_experts
(EngineCore_DP0 pid=14609) INFO 12-16 12:40:51 [mxfp4.py:162] Using Marlin backend
Loading safetensors checkpoint shards: 0% Completed | 0/3 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 33% Completed | 1/3 [00:00<00:01, 1.94it/s]
Loading safetensors checkpoint shards: 67% Completed | 2/3 [00:01<00:00, 1.71it/s]
Loading safetensors checkpoint shards: 100% Completed | 3/3 [00:01<00:00, 1.75it/s]
Loading safetensors checkpoint shards: 100% Completed | 3/3 [00:01<00:00, 1.76it/s]
(EngineCore_DP0 pid=14609)
(EngineCore_DP0 pid=14609) INFO 12-16 12:40:53 [default_loader.py:308] Loading weights took 1.82 seconds
(EngineCore_DP0 pid=14609) WARNING 12-16 12:40:53 [marlin_utils_fp4.py:226] Your GPU does not have native support for FP4 computation but FP4 quantization is being used. Weight-only FP4 compression will be used leveraging the Marlin kernel. This may degrade performance for compute-heavy workloads.
(EngineCore_DP0 pid=14609) INFO 12-16 12:40:53 [gpu_model_runner.py:3549] Model loading took 13.7194 GiB memory and 4.125383 seconds
(EngineCore_DP0 pid=14609) INFO 12-16 12:40:58 [backends.py:655] Using cache directory: /root/.cache/vllm/torch_compile_cache/76ebb93956/rank_0_0/backbone for vLLM's torch.compile
(EngineCore_DP0 pid=14609) INFO 12-16 12:40:58 [backends.py:715] Dynamo bytecode transform time: 3.96 s
(EngineCore_DP0 pid=14609) INFO 12-16 12:40:58 [backends.py:257] Cache the graph for dynamic shape for later use
(EngineCore_DP0 pid=14609) INFO 12-16 12:41:01 [backends.py:288] Compiling a graph for dynamic shape takes 3.01 s
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] EngineCore failed to start.
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] Traceback (most recent call last):
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/v1/engine/core.py", line 834, in run_engine_core
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] engine_core = EngineCoreProc(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/v1/engine/core.py", line 610, in __init__
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] super().__init__(
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/v1/engine/core.py", line 109, in __init__
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] num_gpu_blocks, num_cpu_blocks, kv_cache_config = self._initialize_kv_caches(
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/v1/engine/core.py", line 235, in _initialize_kv_caches
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] available_gpu_memory = self.model_executor.determine_available_memory()
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/v1/executor/abstract.py", line 126, in determine_available_memory
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self.collective_rpc("determine_available_memory")
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/v1/executor/uniproc_executor.py", line 75, in collective_rpc
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] result = run_method(self.driver_worker, method, args, kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/v1/serial_utils.py", line 479, in run_method
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return func(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/utils/_contextlib.py", line 120, in decorate_context
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return func(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/v1/worker/gpu_worker.py", line 324, in determine_available_memory
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] self.model_runner.profile_run()
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/v1/worker/gpu_model_runner.py", line 4357, in profile_run
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] hidden_states, last_hidden_states = self._dummy_run(
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/utils/_contextlib.py", line 120, in decorate_context
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return func(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/v1/worker/gpu_model_runner.py", line 4071, in _dummy_run
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] outputs = self.model(
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/compilation/cuda_graph.py", line 126, in __call__
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self.runnable(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self._call_impl(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1786, in _call_impl
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return forward_call(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/model_executor/models/gpt_oss.py", line 723, in forward
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self.model(input_ids, positions, intermediate_tensors, inputs_embeds)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/compilation/decorators.py", line 514, in __call__
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] output = TorchCompileWithNoGuardsWrapper.__call__(self, *args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/compilation/wrapper.py", line 171, in __call__
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self._compiled_callable(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/_dynamo/eval_frame.py", line 832, in compile_wrapper
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return fn(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/model_executor/models/gpt_oss.py", line 277, in forward
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] def forward(
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/_dynamo/eval_frame.py", line 1044, in _fn
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return fn(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/compilation/caching.py", line 54, in __call__
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self.optimized_call(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/fx/graph_module.py", line 837, in call_wrapped
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self._wrapped_call(self, *args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/fx/graph_module.py", line 413, in __call__
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] raise e
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/fx/graph_module.py", line 400, in __call__
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self._call_impl(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1786, in _call_impl
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return forward_call(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "<eval_with_key>.50", line 209, in forward
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] submod_2 = self.submod_2(getitem_3, s72, l_self_modules_layers_modules_0_modules_attn_modules_o_proj_parameters_weight_, l_self_modules_layers_modules_0_modules_attn_modules_o_proj_parameters_bias_, l_self_modules_layers_modules_0_modules_post_attention_layernorm_parameters_weight_, getitem_4, l_self_modules_layers_modules_0_modules_mlp_modules_router_parameters_weight_, l_self_modules_layers_modules_0_modules_mlp_modules_router_parameters_bias_, l_self_modules_layers_modules_1_modules_input_layernorm_parameters_weight_, l_self_modules_layers_modules_1_modules_attn_modules_qkv_proj_parameters_weight_, l_self_modules_layers_modules_1_modules_attn_modules_qkv_proj_parameters_bias_, l_positions_, l_self_modules_layers_modules_0_modules_attn_modules_rotary_emb_buffers_cos_sin_cache_); getitem_3 = l_self_modules_layers_modules_0_modules_attn_modules_o_proj_parameters_weight_ = l_self_modules_layers_modules_0_modules_attn_modules_o_proj_parameters_bias_ = l_self_modules_layers_modules_0_modules_post_attention_layernorm_parameters_weight_ = getitem_4 = l_self_modules_layers_modules_0_modules_mlp_modules_router_parameters_weight_ = l_self_modules_layers_modules_0_modules_mlp_modules_router_parameters_bias_ = l_self_modules_layers_modules_1_modules_input_layernorm_parameters_weight_ = l_self_modules_layers_modules_1_modules_attn_modules_qkv_proj_parameters_weight_ = l_self_modules_layers_modules_1_modules_attn_modules_qkv_proj_parameters_bias_ = None
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/compilation/cuda_graph.py", line 126, in __call__
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self.runnable(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/compilation/piecewise_backend.py", line 93, in __call__
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self.compiled_graph_for_general_shape(*args)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/_inductor/standalone_compile.py", line 63, in __call__
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self._compiled_fn(*args)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/_dynamo/eval_frame.py", line 1044, in _fn
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return fn(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/_functorch/aot_autograd.py", line 1130, in forward
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return compiled_fn(full_args)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/_functorch/_aot_autograd/runtime_wrappers.py", line 353, in runtime_wrapper
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] all_outs = call_func_at_runtime_with_args(
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/_functorch/_aot_autograd/utils.py", line 129, in call_func_at_runtime_with_args
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] out = normalize_as_list(f(args))
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/_functorch/_aot_autograd/runtime_wrappers.py", line 526, in wrapper
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return compiled_fn(runtime_args)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/_inductor/output_code.py", line 613, in __call__
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self.current_callable(inputs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/_inductor/utils.py", line 2962, in run
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] out = model(new_inputs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/tmp/torchinductor_token/3s/c3scxjen4xvb6yt77aqsailqhvbfyslfwmlffialkjtwqdnicmpz.py", line 1014, in call
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] buf5 = torch.ops.vllm.moe_forward.default(buf4, buf3, 'model.layers.0.mlp.experts')
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/_ops.py", line 841, in __call__
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self._op(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/model_executor/layers/fused_moe/layer.py", line 2101, in moe_forward
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self.forward_impl(hidden_states, router_logits)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/model_executor/layers/fused_moe/layer.py", line 1960, in forward_impl
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] final_hidden_states = self.quant_method.apply(
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/model_executor/layers/quantization/mxfp4.py", line 922, in apply
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return fused_marlin_moe(
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/model_executor/layers/fused_moe/fused_marlin_moe.py", line 318, in fused_marlin_moe
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] sorted_token_ids, expert_ids, num_tokens_post_padded = moe_align_block_size(
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/model_executor/layers/fused_moe/moe_align_block_size.py", line 79, in moe_align_block_size
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] ops.moe_align_block_size(
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/home/vllm/vllm/_custom_ops.py", line 1881, in moe_align_block_size
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] torch.ops._moe_C.moe_align_block_size(
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/_ops.py", line 1255, in __call__
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] return self._op(*args, **kwargs)
(EngineCore_DP0 pid=14609) ERROR 12-16 12:41:02 [core.py:843] RuntimeError: _moe_C::moe_align_block_size() is missing value for argument 'maybe_expert_map'. Declaration: _moe_C::moe_align_block_size(Tensor topk_ids, int num_experts, int block_size, Tensor($0! -> ) sorted_token_ids, Tensor($1! -> ) experts_ids, Tensor($2! -> ) num_tokens_post_pad, Tensor? maybe_expert_map) -> ()
(EngineCore_DP0 pid=14609) Process EngineCore_DP0:
(EngineCore_DP0 pid=14609) Traceback (most recent call last):
(EngineCore_DP0 pid=14609) File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
(EngineCore_DP0 pid=14609) self.run()
(EngineCore_DP0 pid=14609) File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
(EngineCore_DP0 pid=14609) self._target(*self._args, **self._kwargs)
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/v1/engine/core.py", line 847, in run_engine_core
(EngineCore_DP0 pid=14609) raise e
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/v1/engine/core.py", line 834, in run_engine_core
(EngineCore_DP0 pid=14609) engine_core = EngineCoreProc(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/v1/engine/core.py", line 610, in __init__
(EngineCore_DP0 pid=14609) super().__init__(
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/v1/engine/core.py", line 109, in __init__
(EngineCore_DP0 pid=14609) num_gpu_blocks, num_cpu_blocks, kv_cache_config = self._initialize_kv_caches(
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/v1/engine/core.py", line 235, in _initialize_kv_caches
(EngineCore_DP0 pid=14609) available_gpu_memory = self.model_executor.determine_available_memory()
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/v1/executor/abstract.py", line 126, in determine_available_memory
(EngineCore_DP0 pid=14609) return self.collective_rpc("determine_available_memory")
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/v1/executor/uniproc_executor.py", line 75, in collective_rpc
(EngineCore_DP0 pid=14609) result = run_method(self.driver_worker, method, args, kwargs)
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/v1/serial_utils.py", line 479, in run_method
(EngineCore_DP0 pid=14609) return func(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/utils/_contextlib.py", line 120, in decorate_context
(EngineCore_DP0 pid=14609) return func(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/v1/worker/gpu_worker.py", line 324, in determine_available_memory
(EngineCore_DP0 pid=14609) self.model_runner.profile_run()
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/v1/worker/gpu_model_runner.py", line 4357, in profile_run
(EngineCore_DP0 pid=14609) hidden_states, last_hidden_states = self._dummy_run(
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/utils/_contextlib.py", line 120, in decorate_context
(EngineCore_DP0 pid=14609) return func(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/v1/worker/gpu_model_runner.py", line 4071, in _dummy_run
(EngineCore_DP0 pid=14609) outputs = self.model(
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/compilation/cuda_graph.py", line 126, in __call__
(EngineCore_DP0 pid=14609) return self.runnable(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
(EngineCore_DP0 pid=14609) return self._call_impl(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1786, in _call_impl
(EngineCore_DP0 pid=14609) return forward_call(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/model_executor/models/gpt_oss.py", line 723, in forward
(EngineCore_DP0 pid=14609) return self.model(input_ids, positions, intermediate_tensors, inputs_embeds)
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/compilation/decorators.py", line 514, in __call__
(EngineCore_DP0 pid=14609) output = TorchCompileWithNoGuardsWrapper.__call__(self, *args, **kwargs)
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/compilation/wrapper.py", line 171, in __call__
(EngineCore_DP0 pid=14609) return self._compiled_callable(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/_dynamo/eval_frame.py", line 832, in compile_wrapper
(EngineCore_DP0 pid=14609) return fn(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/model_executor/models/gpt_oss.py", line 277, in forward
(EngineCore_DP0 pid=14609) def forward(
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/_dynamo/eval_frame.py", line 1044, in _fn
(EngineCore_DP0 pid=14609) return fn(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/compilation/caching.py", line 54, in __call__
(EngineCore_DP0 pid=14609) return self.optimized_call(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/fx/graph_module.py", line 837, in call_wrapped
(EngineCore_DP0 pid=14609) return self._wrapped_call(self, *args, **kwargs)
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/fx/graph_module.py", line 413, in __call__
(EngineCore_DP0 pid=14609) raise e
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/fx/graph_module.py", line 400, in __call__
(EngineCore_DP0 pid=14609) return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
(EngineCore_DP0 pid=14609) return self._call_impl(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1786, in _call_impl
(EngineCore_DP0 pid=14609) return forward_call(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "<eval_with_key>.50", line 209, in forward
(EngineCore_DP0 pid=14609) submod_2 = self.submod_2(getitem_3, s72, l_self_modules_layers_modules_0_modules_attn_modules_o_proj_parameters_weight_, l_self_modules_layers_modules_0_modules_attn_modules_o_proj_parameters_bias_, l_self_modules_layers_modules_0_modules_post_attention_layernorm_parameters_weight_, getitem_4, l_self_modules_layers_modules_0_modules_mlp_modules_router_parameters_weight_, l_self_modules_layers_modules_0_modules_mlp_modules_router_parameters_bias_, l_self_modules_layers_modules_1_modules_input_layernorm_parameters_weight_, l_self_modules_layers_modules_1_modules_attn_modules_qkv_proj_parameters_weight_, l_self_modules_layers_modules_1_modules_attn_modules_qkv_proj_parameters_bias_, l_positions_, l_self_modules_layers_modules_0_modules_attn_modules_rotary_emb_buffers_cos_sin_cache_); getitem_3 = l_self_modules_layers_modules_0_modules_attn_modules_o_proj_parameters_weight_ = l_self_modules_layers_modules_0_modules_attn_modules_o_proj_parameters_bias_ = l_self_modules_layers_modules_0_modules_post_attention_layernorm_parameters_weight_ = getitem_4 = l_self_modules_layers_modules_0_modules_mlp_modules_router_parameters_weight_ = l_self_modules_layers_modules_0_modules_mlp_modules_router_parameters_bias_ = l_self_modules_layers_modules_1_modules_input_layernorm_parameters_weight_ = l_self_modules_layers_modules_1_modules_attn_modules_qkv_proj_parameters_weight_ = l_self_modules_layers_modules_1_modules_attn_modules_qkv_proj_parameters_bias_ = None
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/compilation/cuda_graph.py", line 126, in __call__
(EngineCore_DP0 pid=14609) return self.runnable(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/compilation/piecewise_backend.py", line 93, in __call__
(EngineCore_DP0 pid=14609) return self.compiled_graph_for_general_shape(*args)
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/_inductor/standalone_compile.py", line 63, in __call__
(EngineCore_DP0 pid=14609) return self._compiled_fn(*args)
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/_dynamo/eval_frame.py", line 1044, in _fn
(EngineCore_DP0 pid=14609) return fn(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/_functorch/aot_autograd.py", line 1130, in forward
(EngineCore_DP0 pid=14609) return compiled_fn(full_args)
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/_functorch/_aot_autograd/runtime_wrappers.py", line 353, in runtime_wrapper
(EngineCore_DP0 pid=14609) all_outs = call_func_at_runtime_with_args(
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/_functorch/_aot_autograd/utils.py", line 129, in call_func_at_runtime_with_args
(EngineCore_DP0 pid=14609) out = normalize_as_list(f(args))
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/_functorch/_aot_autograd/runtime_wrappers.py", line 526, in wrapper
(EngineCore_DP0 pid=14609) return compiled_fn(runtime_args)
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/_inductor/output_code.py", line 613, in __call__
(EngineCore_DP0 pid=14609) return self.current_callable(inputs)
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/_inductor/utils.py", line 2962, in run
(EngineCore_DP0 pid=14609) out = model(new_inputs)
(EngineCore_DP0 pid=14609) File "/tmp/torchinductor_token/3s/c3scxjen4xvb6yt77aqsailqhvbfyslfwmlffialkjtwqdnicmpz.py", line 1014, in call
(EngineCore_DP0 pid=14609) buf5 = torch.ops.vllm.moe_forward.default(buf4, buf3, 'model.layers.0.mlp.experts')
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/_ops.py", line 841, in __call__
(EngineCore_DP0 pid=14609) return self._op(*args, **kwargs)
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/model_executor/layers/fused_moe/layer.py", line 2101, in moe_forward
(EngineCore_DP0 pid=14609) return self.forward_impl(hidden_states, router_logits)
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/model_executor/layers/fused_moe/layer.py", line 1960, in forward_impl
(EngineCore_DP0 pid=14609) final_hidden_states = self.quant_method.apply(
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/model_executor/layers/quantization/mxfp4.py", line 922, in apply
(EngineCore_DP0 pid=14609) return fused_marlin_moe(
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/model_executor/layers/fused_moe/fused_marlin_moe.py", line 318, in fused_marlin_moe
(EngineCore_DP0 pid=14609) sorted_token_ids, expert_ids, num_tokens_post_padded = moe_align_block_size(
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/model_executor/layers/fused_moe/moe_align_block_size.py", line 79, in moe_align_block_size
(EngineCore_DP0 pid=14609) ops.moe_align_block_size(
(EngineCore_DP0 pid=14609) File "/home/vllm/vllm/_custom_ops.py", line 1881, in moe_align_block_size
(EngineCore_DP0 pid=14609) torch.ops._moe_C.moe_align_block_size(
(EngineCore_DP0 pid=14609) File "/usr/local/lib/python3.10/dist-packages/torch/_ops.py", line 1255, in __call__
(EngineCore_DP0 pid=14609) return self._op(*args, **kwargs)
(EngineCore_DP0 pid=14609) RuntimeError: _moe_C::moe_align_block_size() is missing value for argument 'maybe_expert_map'. Declaration: _moe_C::moe_align_block_size(Tensor topk_ids, int num_experts, int block_size, Tensor($0! -> ) sorted_token_ids, Tensor($1! -> ) experts_ids, Tensor($2! -> ) num_tokens_post_pad, Tensor? maybe_expert_map) -> ()
[rank0]:[W1216 12:41:02.145493395 ProcessGroupNCCL.cpp:1524] Warning: WARNING: destroy_process_group() was not called before program exit, which can leak resources. For more info, please see https://pytorch.org/docs/stable/distributed.html#shutdown (function operator())
(APIServer pid=14588) Traceback (most recent call last):
(APIServer pid=14588) File "/usr/lib/python3.10/runpy.py", line 196, in _run_module_as_main
(APIServer pid=14588) return _run_code(code, main_globals, None,
(APIServer pid=14588) File "/usr/lib/python3.10/runpy.py", line 86, in _run_code
(APIServer pid=14588) exec(code, run_globals)
(APIServer pid=14588) File "/home/vllm/vllm/entrypoints/openai/api_server.py", line 1891, in <module>
(APIServer pid=14588) uvloop.run(run_server(args))
(APIServer pid=14588) File "/usr/local/lib/python3.10/dist-packages/uvloop/__init__.py", line 69, in run
(APIServer pid=14588) return loop.run_until_complete(wrapper())
(APIServer pid=14588) File "uvloop/loop.pyx", line 1518, in uvloop.loop.Loop.run_until_complete
(APIServer pid=14588) File "/usr/local/lib/python3.10/dist-packages/uvloop/__init__.py", line 48, in wrapper
(APIServer pid=14588) return await main
(APIServer pid=14588) File "/home/vllm/vllm/entrypoints/openai/api_server.py", line 1819, in run_server
(APIServer pid=14588) await run_server_worker(listen_address, sock, args, **uvicorn_kwargs)
(APIServer pid=14588) File "/home/vllm/vllm/entrypoints/openai/api_server.py", line 1838, in run_server_worker
(APIServer pid=14588) async with build_async_engine_client(
(APIServer pid=14588) File "/usr/lib/python3.10/contextlib.py", line 199, in __aenter__
(APIServer pid=14588) return await anext(self.gen)
(APIServer pid=14588) File "/home/vllm/vllm/entrypoints/openai/api_server.py", line 183, in build_async_engine_client
(APIServer pid=14588) async with build_async_engine_client_from_engine_args(
(APIServer pid=14588) File "/usr/lib/python3.10/contextlib.py", line 199, in __aenter__
(APIServer pid=14588) return await anext(self.gen)
(APIServer pid=14588) File "/home/vllm/vllm/entrypoints/openai/api_server.py", line 224, in build_async_engine_client_from_engine_args
(APIServer pid=14588) async_llm = AsyncLLM.from_vllm_config(
(APIServer pid=14588) File "/home/vllm/vllm/v1/engine/async_llm.py", line 223, in from_vllm_config
(APIServer pid=14588) return cls(
(APIServer pid=14588) File "/home/vllm/vllm/v1/engine/async_llm.py", line 134, in __init__
(APIServer pid=14588) self.engine_core = EngineCoreClient.make_async_mp_client(
(APIServer pid=14588) File "/home/vllm/vllm/v1/engine/core_client.py", line 121, in make_async_mp_client
(APIServer pid=14588) return AsyncMPClient(*client_args)
(APIServer pid=14588) File "/home/vllm/vllm/v1/engine/core_client.py", line 810, in __init__
(APIServer pid=14588) super().__init__(
(APIServer pid=14588) File "/home/vllm/vllm/v1/engine/core_client.py", line 471, in __init__
(APIServer pid=14588) with launch_core_engines(vllm_config, executor_class, log_stats) as (
(APIServer pid=14588) File "/usr/lib/python3.10/contextlib.py", line 142, in __exit__
(APIServer pid=14588) next(self.gen)
(APIServer pid=14588) File "/home/vllm/vllm/v1/engine/utils.py", line 903, in launch_core_engines
(APIServer pid=14588) wait_for_engine_startup(
(APIServer pid=14588) File "/home/vllm/vllm/v1/engine/utils.py", line 960, in wait_for_engine_startup
(APIServer pid=14588) raise RuntimeError(
(APIServer pid=14588) RuntimeError: Engine core initialization failed. See root cause above. Failed core proc(s): {}
解決了 vLLM 安裝的問題之後,另外又出現 CUDA Driver 太舊的錯誤訊息,即便升級 Nvidia Driver 之後還是無法直接將打包好的 image 跑在 K8S 的環境裡,因為檸檬爸是使用 AKS 加 Device Plugin 的方式構建 GPU 的環境,這是一個比較簡易的方式,像要比較完整的環境,還是要考慮使用 GPU Operator。
025-12-16 14:49:44,345 - INFO - Starting vLLM server with command: /usr/bin/python3.10 -m vllm.entrypoints.openai.api_server --model /mnt/gpt-oss-20b --served-model-name openai/gpt-oss-20b --port 7000 --tensor_parallel_size 1 --gpu_memory_utilization 0.65 --max_model_len 6600 --task generate
WARNING 12-16 14:49:49 [argparse_utils.py:82] argument 'task' is deprecated
(APIServer pid=9353) INFO 12-16 14:49:49 [api_server.py:1772] vLLM API server version 0.12.0
(APIServer pid=9353) INFO 12-16 14:49:49 [utils.py:253] non-default args: {'port': 7000, 'model': '/mnt/gpt-oss-20b', 'task': 'generate', 'max_model_len': 6600, 'served_model_name': ['openai/gpt-oss-20b'], 'gpu_memory_utilization': 0.65}
(APIServer pid=9353) INFO 12-16 14:49:49 [model.py:637] Resolved architecture: GptOssForCausalLM
(APIServer pid=9353) ERROR 12-16 14:49:49 [repo_utils.py:65] Error retrieving safetensors: Repo id must be in the form 'repo_name' or 'namespace/repo_name': '/mnt/gpt-oss-20b'. Use `repo_type` argument if needed., retrying 1 of 2
(APIServer pid=9353) ERROR 12-16 14:49:51 [repo_utils.py:63] Error retrieving safetensors: Repo id must be in the form 'repo_name' or 'namespace/repo_name': '/mnt/gpt-oss-20b'. Use `repo_type` argument if needed.
(APIServer pid=9353) INFO 12-16 14:49:51 [model.py:2086] Downcasting torch.float32 to torch.bfloat16.
(APIServer pid=9353) INFO 12-16 14:49:51 [model.py:1750] Using max model len 6600
(APIServer pid=9353) INFO 12-16 14:49:53 [scheduler.py:228] Chunked prefill is enabled with max_num_batched_tokens=2048.
(APIServer pid=9353) INFO 12-16 14:49:53 [config.py:274] Overriding max cuda graph capture size to 1024 for performance.
(EngineCore_DP0 pid=9378) INFO 12-16 14:49:59 [core.py:93] Initializing a V1 LLM engine (v0.12.0) with config: model='/mnt/gpt-oss-20b', speculative_config=None, tokenizer='/mnt/gpt-oss-20b', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=6600, download_dir=None, load_format=auto, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, disable_custom_all_reduce=False, quantization=mxfp4, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_fallback=False, disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='openai_gptoss', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01), seed=0, served_model_name=openai/gpt-oss-20b, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'level': None, 'mode': <CompilationMode.VLLM_COMPILE: 3>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['none'], 'splitting_ops': ['vllm::unified_attention', 'vllm::unified_attention_with_output', 'vllm::unified_mla_attention', 'vllm::unified_mla_attention_with_output', 'vllm::mamba_mixer2', 'vllm::mamba_mixer', 'vllm::short_conv', 'vllm::linear_attention', 'vllm::plamo2_mamba_mixer', 'vllm::gdn_attention_core', 'vllm::kda_attention', 'vllm::sparse_attn_indexer'], 'compile_mm_encoder': False, 'compile_sizes': [], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.FULL_AND_PIECEWISE: (2, 1)>, 'cudagraph_num_of_warmups': 1, 'cudagraph_capture_sizes': [1, 2, 4, 8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96, 104, 112, 120, 128, 136, 144, 152, 160, 168, 176, 184, 192, 200, 208, 216, 224, 232, 240, 248, 256, 272, 288, 304, 320, 336, 352, 368, 384, 400, 416, 432, 448, 464, 480, 496, 512, 528, 544, 560, 576, 592, 608, 624, 640, 656, 672, 688, 704, 720, 736, 752, 768, 784, 800, 816, 832, 848, 864, 880, 896, 912, 928, 944, 960, 976, 992, 1008, 1024], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': False, 'fuse_act_quant': False, 'fuse_attn_quant': False, 'eliminate_noops': True, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 1024, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>}, 'local_cache_dir': None}
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] EngineCore failed to start.
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] Traceback (most recent call last):
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/v1/engine/core.py", line 834, in run_engine_core
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] engine_core = EngineCoreProc(*args, **kwargs)
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/v1/engine/core.py", line 610, in __init__
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] super().__init__(
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/v1/engine/core.py", line 102, in __init__
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] self.model_executor = executor_class(vllm_config)
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/v1/executor/abstract.py", line 101, in __init__
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] self._init_executor()
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/v1/executor/uniproc_executor.py", line 46, in _init_executor
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] self.driver_worker.init_worker(all_kwargs=[kwargs])
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/v1/worker/worker_base.py", line 255, in init_worker
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] worker_class = resolve_obj_by_qualname(
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/utils/import_utils.py", line 122, in resolve_obj_by_qualname
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] module = importlib.import_module(module_name)
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/lib/python3.10/importlib/__init__.py", line 126, in import_module
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] return _bootstrap._gcd_import(name[level:], package, level)
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "<frozen importlib._bootstrap>", line 1050, in _gcd_import
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "<frozen importlib._bootstrap_external>", line 883, in exec_module
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/v1/worker/gpu_worker.py", line 54, in <module>
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] from vllm.v1.worker.gpu_model_runner import GPUModelRunner
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/v1/worker/gpu_model_runner.py", line 140, in <module>
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] from vllm.v1.spec_decode.eagle import EagleProposer
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/v1/spec_decode/eagle.py", line 30, in <module>
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] from vllm.v1.attention.backends.flash_attn import FlashAttentionMetadata
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/v1/attention/backends/flash_attn.py", line 230, in <module>
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] class FlashAttentionMetadataBuilder(AttentionMetadataBuilder[FlashAttentionMetadata]):
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/v1/attention/backends/flash_attn.py", line 251, in FlashAttentionMetadataBuilder
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] if get_flash_attn_version() == 3
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/attention/utils/fa_utils.py", line 71, in get_flash_attn_version
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] if not is_fa_version_supported(fa_version):
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/vllm_flash_attn/flash_attn_interface.py", line 68, in is_fa_version_supported
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] return _is_fa2_supported(device)[0]
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/vllm/vllm_flash_attn/flash_attn_interface.py", line 43, in _is_fa2_supported
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] if torch.cuda.get_device_capability(device)[0] < 8:
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/cuda/__init__.py", line 598, in get_device_capability
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] prop = get_device_properties(device)
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/cuda/__init__.py", line 614, in get_device_properties
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] _lazy_init() # will define _get_device_properties
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] File "/usr/local/lib/python3.10/dist-packages/torch/cuda/__init__.py", line 410, in _lazy_init
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] torch._C._cuda_init()
(EngineCore_DP0 pid=9378) ERROR 12-16 14:50:00 [core.py:843] RuntimeError: The NVIDIA driver on your system is too old (found version 12020). Please update your GPU driver by downloading and installing a new version from the URL: http://www.nvidia.com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch version that has been compiled with your version of the CUDA driver.
(EngineCore_DP0 pid=9378) Process EngineCore_DP0:
(EngineCore_DP0 pid=9378) Traceback (most recent call last):
(EngineCore_DP0 pid=9378) File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
(EngineCore_DP0 pid=9378) self.run()
(EngineCore_DP0 pid=9378) File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
(EngineCore_DP0 pid=9378) self._target(*self._args, **self._kwargs)
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/engine/core.py", line 847, in run_engine_core
(EngineCore_DP0 pid=9378) raise e
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/engine/core.py", line 834, in run_engine_core
(EngineCore_DP0 pid=9378) engine_core = EngineCoreProc(*args, **kwargs)
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/engine/core.py", line 610, in __init__
(EngineCore_DP0 pid=9378) super().__init__(
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/engine/core.py", line 102, in __init__
(EngineCore_DP0 pid=9378) self.model_executor = executor_class(vllm_config)
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/executor/abstract.py", line 101, in __init__
(EngineCore_DP0 pid=9378) self._init_executor()
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/executor/uniproc_executor.py", line 46, in _init_executor
(EngineCore_DP0 pid=9378) self.driver_worker.init_worker(all_kwargs=[kwargs])
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/worker/worker_base.py", line 255, in init_worker
(EngineCore_DP0 pid=9378) worker_class = resolve_obj_by_qualname(
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/utils/import_utils.py", line 122, in resolve_obj_by_qualname
(EngineCore_DP0 pid=9378) module = importlib.import_module(module_name)
(EngineCore_DP0 pid=9378) File "/usr/lib/python3.10/importlib/__init__.py", line 126, in import_module
(EngineCore_DP0 pid=9378) return _bootstrap._gcd_import(name[level:], package, level)
(EngineCore_DP0 pid=9378) File "<frozen importlib._bootstrap>", line 1050, in _gcd_import
(EngineCore_DP0 pid=9378) File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
(EngineCore_DP0 pid=9378) File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
(EngineCore_DP0 pid=9378) File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
(EngineCore_DP0 pid=9378) File "<frozen importlib._bootstrap_external>", line 883, in exec_module
(EngineCore_DP0 pid=9378) File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/worker/gpu_worker.py", line 54, in <module>
(EngineCore_DP0 pid=9378) from vllm.v1.worker.gpu_model_runner import GPUModelRunner
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/worker/gpu_model_runner.py", line 140, in <module>
(EngineCore_DP0 pid=9378) from vllm.v1.spec_decode.eagle import EagleProposer
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/spec_decode/eagle.py", line 30, in <module>
(EngineCore_DP0 pid=9378) from vllm.v1.attention.backends.flash_attn import FlashAttentionMetadata
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/attention/backends/flash_attn.py", line 230, in <module>
(EngineCore_DP0 pid=9378) class FlashAttentionMetadataBuilder(AttentionMetadataBuilder[FlashAttentionMetadata]):
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/attention/backends/flash_attn.py", line 251, in FlashAttentionMetadataBuilder
(EngineCore_DP0 pid=9378) if get_flash_attn_version() == 3
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/attention/utils/fa_utils.py", line 71, in get_flash_attn_version
(EngineCore_DP0 pid=9378) if not is_fa_version_supported(fa_version):
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/vllm_flash_attn/flash_attn_interface.py", line 68, in is_fa_version_supported
(EngineCore_DP0 pid=9378) return _is_fa2_supported(device)[0]
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/vllm/vllm_flash_attn/flash_attn_interface.py", line 43, in _is_fa2_supported
(EngineCore_DP0 pid=9378) if torch.cuda.get_device_capability(device)[0] < 8:
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/torch/cuda/__init__.py", line 598, in get_device_capability
(EngineCore_DP0 pid=9378) prop = get_device_properties(device)
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/torch/cuda/__init__.py", line 614, in get_device_properties
(EngineCore_DP0 pid=9378) _lazy_init() # will define _get_device_properties
(EngineCore_DP0 pid=9378) File "/usr/local/lib/python3.10/dist-packages/torch/cuda/__init__.py", line 410, in _lazy_init
(EngineCore_DP0 pid=9378) torch._C._cuda_init()
(EngineCore_DP0 pid=9378) RuntimeError: The NVIDIA driver on your system is too old (found version 12020). Please update your GPU driver by downloading and installing a new version from the URL: http://www.nvidia.com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch version that has been compiled with your version of the CUDA driver.
(APIServer pid=9353) Traceback (most recent call last):
(APIServer pid=9353) File "/usr/lib/python3.10/runpy.py", line 196, in _run_module_as_main
(APIServer pid=9353) return _run_code(code, main_globals, None,
(APIServer pid=9353) File "/usr/lib/python3.10/runpy.py", line 86, in _run_code
(APIServer pid=9353) exec(code, run_globals)
(APIServer pid=9353) File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/openai/api_server.py", line 1891, in <module>
(APIServer pid=9353) uvloop.run(run_server(args))
(APIServer pid=9353) File "/usr/local/lib/python3.10/dist-packages/uvloop/__init__.py", line 69, in run
(APIServer pid=9353) return loop.run_until_complete(wrapper())
(APIServer pid=9353) File "uvloop/loop.pyx", line 1518, in uvloop.loop.Loop.run_until_complete
(APIServer pid=9353) File "/usr/local/lib/python3.10/dist-packages/uvloop/__init__.py", line 48, in wrapper
(APIServer pid=9353) return await main
(APIServer pid=9353) File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/openai/api_server.py", line 1819, in run_server
(APIServer pid=9353) await run_server_worker(listen_address, sock, args, **uvicorn_kwargs)
(APIServer pid=9353) File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/openai/api_server.py", line 1838, in run_server_worker
(APIServer pid=9353) async with build_async_engine_client(
(APIServer pid=9353) File "/usr/lib/python3.10/contextlib.py", line 199, in __aenter__
(APIServer pid=9353) return await anext(self.gen)
(APIServer pid=9353) File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/openai/api_server.py", line 183, in build_async_engine_client
(APIServer pid=9353) async with build_async_engine_client_from_engine_args(
(APIServer pid=9353) File "/usr/lib/python3.10/contextlib.py", line 199, in __aenter__
(APIServer pid=9353) return await anext(self.gen)
(APIServer pid=9353) File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/openai/api_server.py", line 224, in build_async_engine_client_from_engine_args
(APIServer pid=9353) async_llm = AsyncLLM.from_vllm_config(
(APIServer pid=9353) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/engine/async_llm.py", line 223, in from_vllm_config
(APIServer pid=9353) return cls(
(APIServer pid=9353) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/engine/async_llm.py", line 134, in __init__
(APIServer pid=9353) self.engine_core = EngineCoreClient.make_async_mp_client(
(APIServer pid=9353) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/engine/core_client.py", line 121, in make_async_mp_client
(APIServer pid=9353) return AsyncMPClient(*client_args)
(APIServer pid=9353) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/engine/core_client.py", line 810, in __init__
(APIServer pid=9353) super().__init__(
(APIServer pid=9353) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/engine/core_client.py", line 471, in __init__
(APIServer pid=9353) with launch_core_engines(vllm_config, executor_class, log_stats) as (
(APIServer pid=9353) File "/usr/lib/python3.10/contextlib.py", line 142, in __exit__
(APIServer pid=9353) next(self.gen)
(APIServer pid=9353) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/engine/utils.py", line 903, in launch_core_engines
(APIServer pid=9353) wait_for_engine_startup(
(APIServer pid=9353) File "/usr/local/lib/python3.10/dist-packages/vllm/v1/engine/utils.py", line 960, in wait_for_engine_startup
(APIServer pid=9353) raise RuntimeError(
(APIServer pid=9353) RuntimeError: Engine core initialization failed. See root cause above. Failed core proc(s): {}這邊牽扯到環境的構建,詳細研究之後發現,要直接驅動一個已經有裝 CUDA 的 image 需要透過 nvidia-docker2 或者是 nvidia-container-cli 去開啟 docker image,如果 nvidia-container-cli 太舊或是與 Nvidia Driver 版本不匹配,就算從 nvidia-smi 看到已經是最新的版本也不能夠將有 CUDA 版本的 Image 跑起來,利用 GPU Operator 配合 K8S 將 GPU 安裝好之後就可以成功執行了。