[GPU] 加速主成分分析 (PCA)
檸檬爸幾年前有分享過一篇主成分分析 (Principle Component Analysis) 原理的文章,由於 PCA 其實就是矩陣的運算,所以非常適合使用分散式運算來做加速,不論是 Spark 或是 GPU 的架構都很適合,Spark MLlib 本身就可以加速 PCA 等機器學習的運算,使用 cuML + GPU 根據 Nvidia Blog 的數據,加速的效果更加明顯,本篇想要紀錄如何導入 GPU 到 PCA 等等傳統的機器學習運算?
詳細內容想方涉法, France, Taiwan, Health, Information Technology
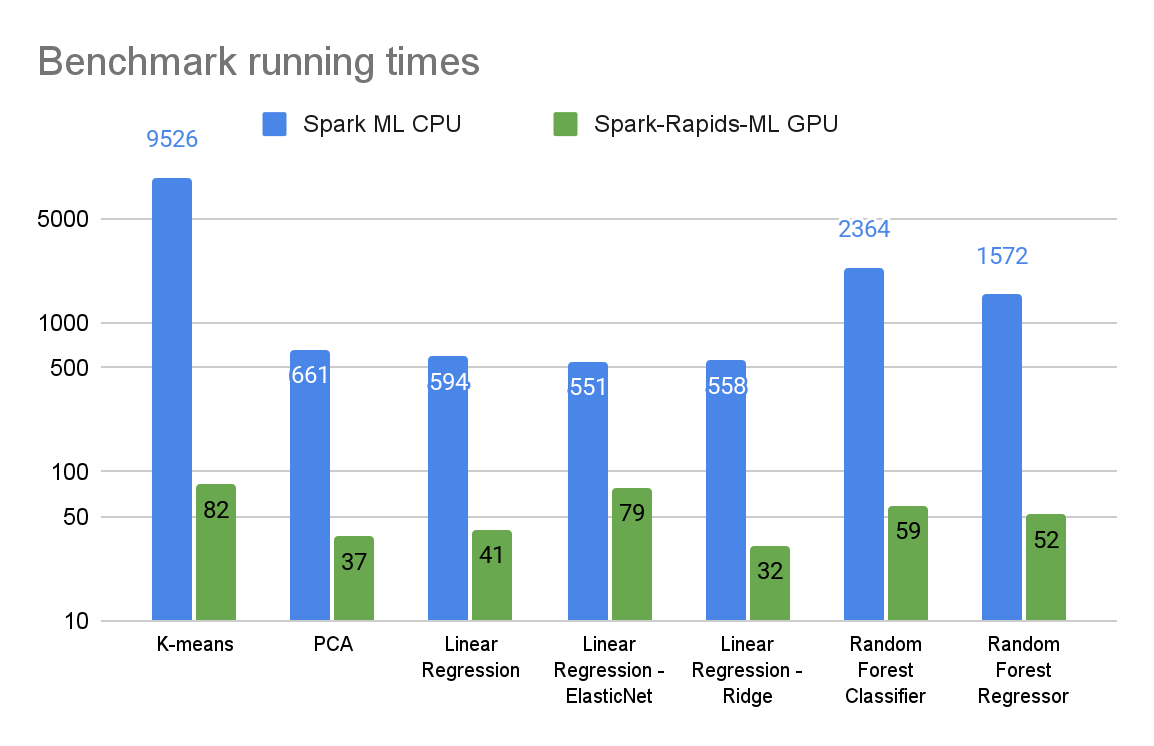
檸檬爸幾年前有分享過一篇主成分分析 (Principle Component Analysis) 原理的文章,由於 PCA 其實就是矩陣的運算,所以非常適合使用分散式運算來做加速,不論是 Spark 或是 GPU 的架構都很適合,Spark MLlib 本身就可以加速 PCA 等機器學習的運算,使用 cuML + GPU 根據 Nvidia Blog 的數據,加速的效果更加明顯,本篇想要紀錄如何導入 GPU 到 PCA 等等傳統的機器學習運算?
詳細內容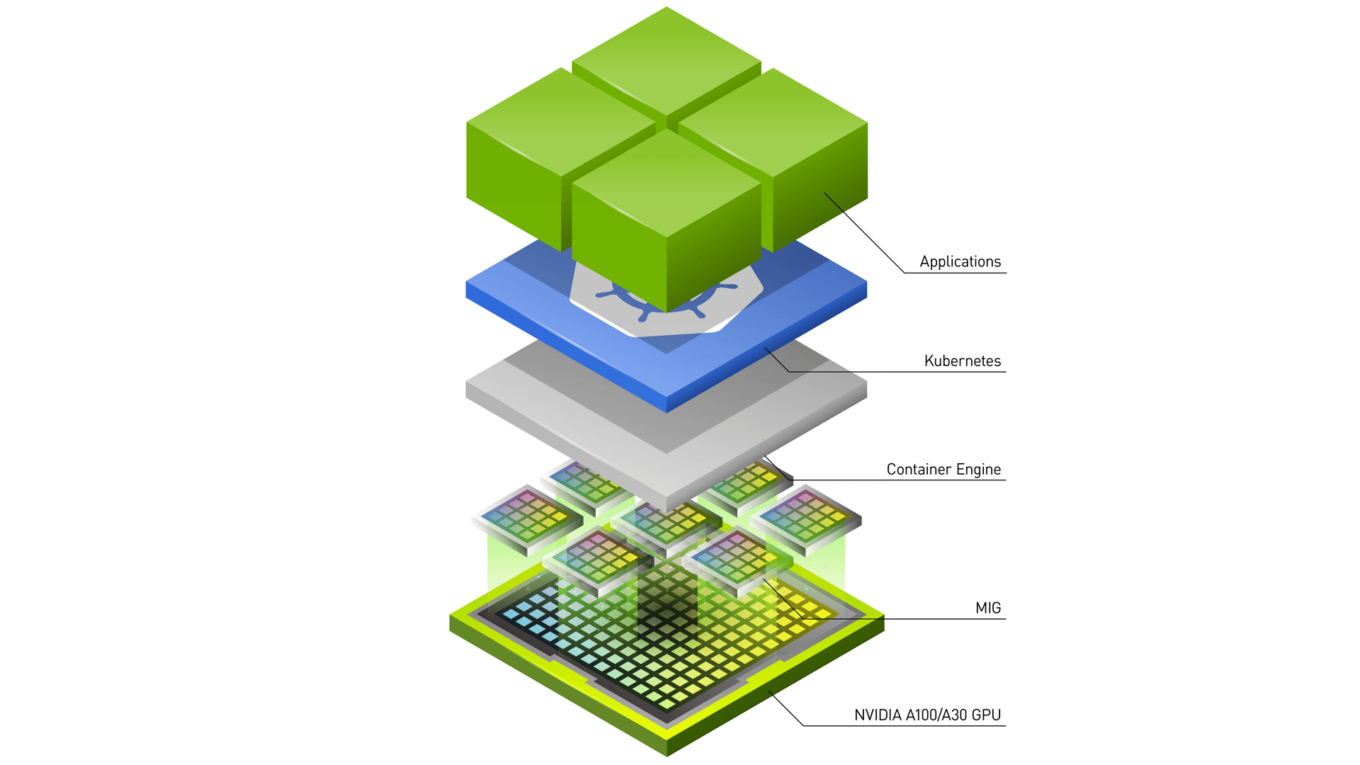
Nvidia 的 GPU 目前是市場上使用的主流,在雲的世界裡面,由於大部分的使用場景是按需 (On Demand),因此 K8S 慢慢地也是雲端管理資源的一個利器,如何在 Kubernetes 上調用 GPU 的資源相對地也越來越普遍,本篇整理了目前網路上可以看到 Nvidia GPU 於操作方法,並且介紹一種簡單實現 GPU Time-Slicing 的設定。
詳細內容
本篇想要記錄一下在 Azure Ubuntu 20.04 x64 VM 上面使用 GPU 的安裝過程,首先需要安裝相關 Nvidia GPU 的 Driver,不過究竟要安裝多少套件各方說法不一,由於之前已經有一組可以使用 GPU 的安裝指令,所以本篇以嘗試使用這組指令為基礎紀錄解決問題的方法,鳥哥的教學告訴我們可以利用 dpkg -l ‘nvidia*’ 的指令得知目前安裝所有 Nvidia GPU 相關的套件總覽,配合這個指令我們可以了解究竟安裝了什麼?
詳細內容
上一篇我們介紹了如何利用 cudf C++ 創建自己可以跑在 GPU 上面的 UDF,本篇我們想要紀錄如何利用 Spark Rapids Examples 提供的編譯環境建造出屬於自己的 jar 可以跑在有 GPU 的 Spark 叢集運算之上。
詳細內容
在上一篇我們成功實作了 HiveUDF,為了要進一步利用 GPU 加速,我們需要去實作 evaluateColumnar 這一個函數,參考 Spark Rapids 的 Github 與 ColumnView 裡面的範例,針對我們想做到的 UDF 我們沒有發現適合的函數去實作針對一個 Array[String] 的過濾程式,所以我們需要自己去實作 Tutorial 裡面所謂的 Native Code Examples,Tutorial 裡面針對 HiveUDF 只有提供一個範例是 StringWordCount,本篇我們紀錄藉由這個範例去實作一個支援 GPU 的 HiveUDF。
詳細內容