[Hadoop] Hdfs Data Integrity with Checksum
使用 Spark/Hadoop 生態系這麼久之後,最近才開始來研究 Hadoop 的 checksum 機制是怎麼運作的?
詳細內容想方涉法, France, Taiwan, Health, Information Technology

使用 Spark/Hadoop 生態系這麼久之後,最近才開始來研究 Hadoop 的 checksum 機制是怎麼運作的?
詳細內容K8S 服務在業界已經是很常用的一個叢集管理技術了,在這邊記錄一些 K8S 的常用指令與利用 Azure Kubernetes 服務實作的一些輸出,關於 Kubernetes 的介紹可以參考以下的 Youtube 影片,讀文件很累的時候可以聽聽 IBM 的工程師是怎麼介紹 K8S。
詳細內容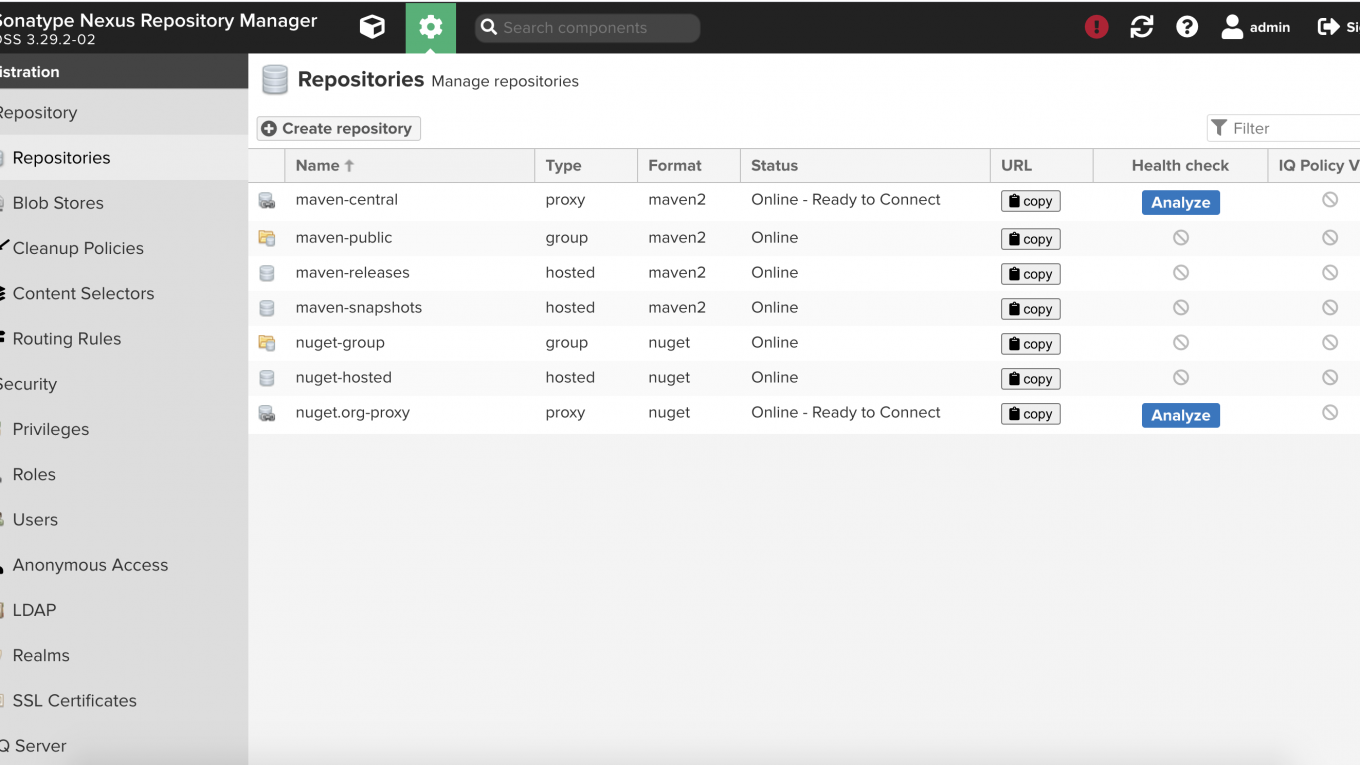
🍋 爸在法國擔任資料工程師的時候,頻繁地使用過 Nexus 這個資源庫倉儲系統,那時候使用 Nexus 主要的原因是因為在一間大公司裡面,常常各個部門之間的專案是互相依賴的,此時為了建置 CICD 的管理機制,他們會導入 Nexus 這樣的系統來分享自己編譯好的 Jar 檔(如果是 Java, Scala 的開發環境),所有使用過 Maven 編譯的開發者應該會 nexus 也不陌生,很多著名的專案都是利用 Nexus 這樣的系統在分享他們的開源程式,例如 Apache Spark 等等,那時候🍋 爸主要是使用為主,本篇要介紹如何部署屬於自己的 Nexus Repository ?
詳細內容在上一篇我們探討了 Hdfs 在 Hadoop 3.1.2 的時候要怎麼安裝?最近由於筆者需要將 Spark 2.4 升到 Spark 3.0 以上,所以順便研究並且探討 Hadoop 3.x 與 Hadoop 2.x 版本的差異,本篇主要參考的是 Data Flair 網站上面的比較差異,我們整理並且精簡 22 項差異中到最重要的 7 項。
詳細內容生物資訊領域是近幾年來很熱門的一個領域,本篇紀錄有關 VCF – Variant Calling Format 基因變異儲存格式檔案的處理過程,有關於 VCF 的簡單介紹可以參考連結,也可以參考 Wikipedia 裡面關於 VCF 的介紹,一個 VCF 檔案大致上長成以下的樣子
詳細內容
介紹另外一個 Python 套件用於套件管理 – Poetry,相較於 pip 的管理方式,poetry 的好處在於當我們刪除掉某一個不需要的 package 的時候,我們可以也把其他相關但是不需要的套件一併刪除,由此可以精簡真正需要的 Python 套件,不會過度增加不必要的 python 套件,以下我們舉實例演釋。
詳細內容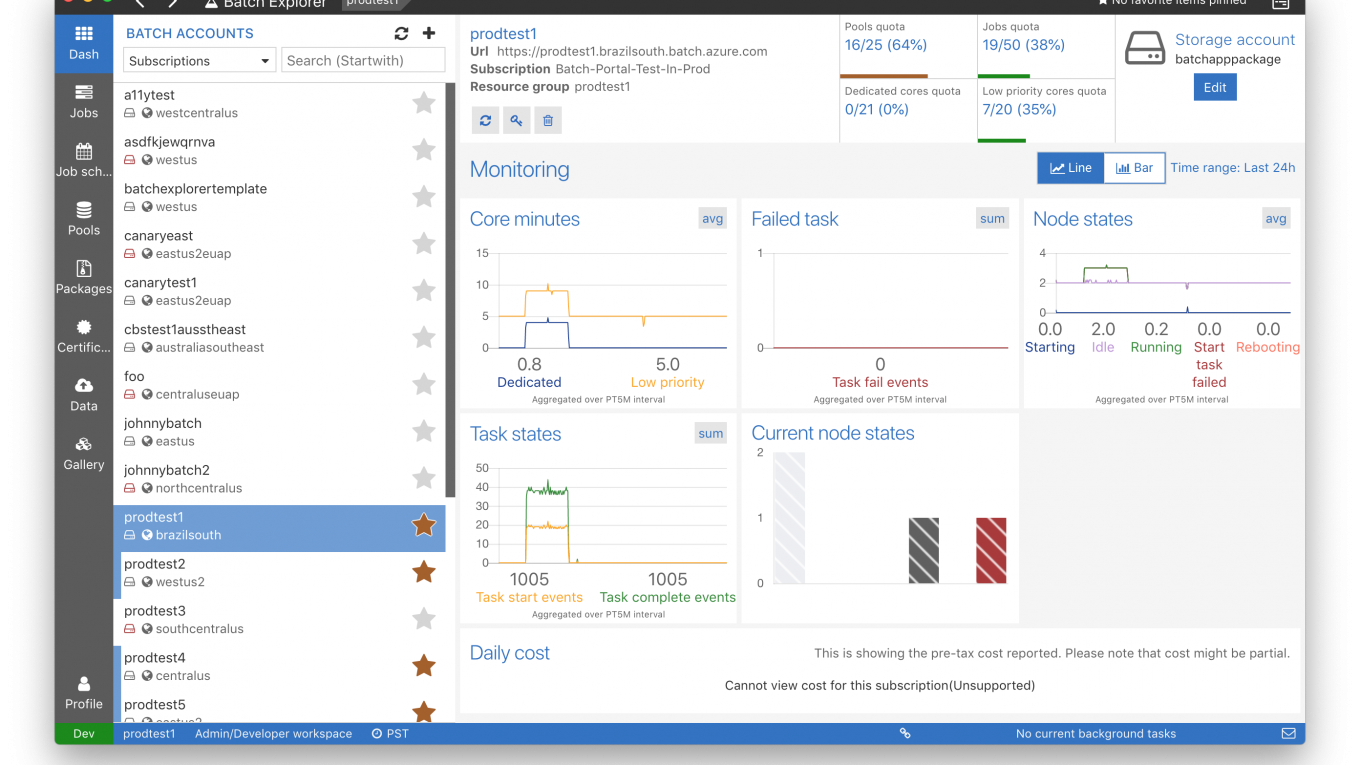
隨著運算需求的增加,無可避免地要進入公有雲的領域,本篇想要整理一下 Azure 在雲端運算提供的方案但是最終專注在 Azure Batch (AZTK) 的介紹,根據 (連結) Azure 在對於 Batch 批次計算的需求大致上有幾個解決方案。
詳細內容
一般來說在視覺化資料庫的方法一般來說如果是 Hive 資料庫可以透過 DBeaver 等等類似 SQL Client 的程式來顯現,但是如果是像是 HBase 的資料庫的話基本上很難快速了解 HBase 裡面存取的檔案全貌,如果可以利用 Hive 用表格的方式呈現的話會比較好理解,本篇想要介紹如何將 HBase 利用 Hive 呈現出來!
詳細內容在大數據的平台上開發大數據應用的時候,如果想要自動化執行不同的 Spark 腳本的話,很常會使用 Apache Oozie 這個軟體,如果想要配合一些 Continuous Delivery 的工具如 Jenkins 和 TeamCity 來使用的時候,需要透過 Oozie 的 WebAPI 來使用,有兩種主要的使用方法,一種是利用 Shell Script 下達 Curl 的指令快速溝通,另一種方式則是利用 Oozie 專案開發的 OozieClient 配合 groovy 或是 Java 的指令運行。
詳細內容Join 是一個在關聯性資料庫裡面很常使用的一個運算元,在大數據資料庫慢慢普及的今天,Join 還是一個幫助我們了解資料關係不可或缺的角色,今天想要討論的是在 Spark 裡面 Join 背後執行的運算原理,筆者在執行 Spark 工作的時候,有時候需要優化資料的運算過程以降低運算所需要的時間,本篇的資料來源可以參考連結,另外筆者也很建議大家觀看以下這一個 Youtube 影片。
詳細內容